- LLM 학습에 사용되는 데이터셋에서 약 1만2천개의 활성 API 키와 비밀번호가 포함된 사실을 발견 - 학습 과정에서 보안이 제대로 관리되지 않을 경우, 심각한 보안 취약점으로 이어질 수 있음을 다시 한번 경고
내용
- 보안 기업 Truffle Security, 2024년 12월 공개된 Common Crawl의 웹 데이터 아카이브를 분석 > Common Crawl : 지난 18년간 축적된 400TB 규모의 웹 데이터를 제공하는 공공 웹 크롤링 저장소 > 이 데이터에서 219가지 유형의 민감한 정보가 포함된 것을 확인 > 아마존웹서비스(AWS) 루트 키, 슬랙(Slack) 웹훅, 메일침프(Mailchimp) API 키 등이 포함 > 11,908개의 API 키 및 비밀번호 중 상당수는 여러 웹사이트에 중복적으로 노출
- 노출된 API 키와 비밀번호가 AI 학습 데이터에 포함될 경우, 보안상 심각한 위험을 초래 ① 안전하지 않은 코딩 방식이 AI를 통해 강화될 가능성 > 하드코딩된 인증 정보를 포함한 데이터를 학습하면, 이후 개발자들에게 보안이 취약한 코드 패턴을 제안할 위험 ② AI가 민감한 정보를 그대로 재현할 가능성 > AI 모델이 특정 API 키나 비밀번호를 학습한 경우, 사용자가 특정 프롬프트를 입력했을 때 해당 정보를 그대로 반환할 가능성
- 철저한 보안 관리가 필요성이 강조됨 > 비밀번호와 API 키를 소스코드에 직접 포함하는 대신, 전용 보안 관리 시스템을 활용 > 코드 리뷰 및 자동화된 보안 점검을 강화 > AI 학습 데이터를 사전에 철저히 검토하고, 민감한 정보가 포함되지 않도록 필터링하는 절차를 강화
기타
- AI 기술이 발전함에 따라 데이터 보안이 더욱 중요해지고 있음을 보여줌 > LLM을 학습시키는 과정에서 보안 조치가 철저히 이루어지지 않으면, AI가 보안 취약점을 학습하고 확산시키는 새로운 위협 요소로 작용할 수 있음 > AI 개발자와 기업들은 보안 강화를 위한 체계적인 접근 방식을 도입해야 함
> XDR을 활용해 의심스러운 송신자, 헤더와 콘텐츠 등을 분석 및 탐지할 수 있도록하고, 직원 교육 강화
- AI를 사용해 오디오/비디오로 직원을 속일 수 있는 딥페이크를 만들 수 있음
> 오디오/비디오를 활용해 사기, 계정탈취, 데이터 유출 등이 이루어질 수 있음
> 임원들의 비정상 지시에 대해 직원이 검증할 수 있는 권한을 부여하거나, 딥페이크를 탐지하는 기술 등이 필요
- AI를 사용해 데이터 유출 위험이 발생할 수 있음
- AI 혁신과 AI 이니셔티브 보안의 적절한 균형이 필요
> AI를 활용한 오용 및 사기에 대해 미리 대비, 솔루션 활용, 위험 평가, 지속적 모니터링 등
AI 혁신
AI 이니셔티브 보안
- 지능형 데이터 분석 및 인사이트 - 자동화된 사기 탐지 및 예방 - 스마트 공공 서비스 등
- 민감 데이터 보호 - 공공 신뢰 유지 및 규제 준수 - 사이버 공격 및 제로데이 취약점으로 부터 인프라 보호 등
3. 해커들의 새로운 타겟–귀사의 API는 안전하십니까?
- API 보안이 중요한 이유
> 웹 트래픽의 83%는 Digital Transformation을 주도하는데 중요한 API에 기인
> 기업의 72%는 API 인증/인가와 관련된 문제로 인해 새로운 앱 및 서비스 개선사항의 출시가 지연되는 것을 경험
> 기업의 44%는 내/외부 API에서 개인정보 보호 및 데이터 유출과 관련된 보안문제를 경험
> API와 웹 애플리케이션을 대상으로 한 악성 요청의 비율은 2022년 54%에서 2023년 70%로 16% 증가
4. 새로운 패러다임에 대응하는 시스템 보안
- 시스템 접근제어의 시작 : 시스템 접속 권한을 가진 내/외부 사용자에 의한 보안사고가 빈번하게 발생
> 등장 전 : 시스템별로 다양한 사용자가 접근해 접속 이력과 로그 분산, 실수로 인한 시스템 장애, 주요 데이터 유출 등의 가능성이 높았음
> 초기 Gateway 모델 : 모든 시스템에 접속하기 위한 단일 게이트웨이를 구축해 접근 경로를 단일화하고, 로그 통합 관리, 실수로 인한 장애 가능성 최소화, 데이터 보호 등 관리 효율성을 마련
- 패러다임 변화와 개인정보 및 기밀정보 유출 방지를 위해 시스템 접근제어에서 바뀌어야 할 핵심 요소
보안 아키텍처 변화 이슈 암묵적 신뢰 -> 비신뢰 (Zero Trust 보안 환경)
클라우드 전환 시 주요 이슈 On-Premise -> Cloud (TCO 비용 절감과 호환성)
위협 대응 주요 이슈 Rule -> 행위 기반 (예측 기반 사전 대응 체계)
- ID 기반 접근 제어 - MFA - 리소스별 보안 환경 - 최소 권한 및 세분화 - 지속적인 감시 및 검증
- 도입, 전환, 운영 비용절감 - 클라우드 전환 용이성 - 클라우드 보안 책임 이슈
- 실시간 분석 대응시간 단축 - 위협 예측 사전 대응
5. 사이버 위협 대응 관점에서 바라보는 개인정보 유출 사고 방지 방안
- 경계 중심 보안에서 복원을 위해 중요자산을 보호하는 대응중심으로 IT 환경 변화
- 이기종 보안 솔루션 운영
- XDR(eXtended Detection & Rseponse)
> 위협 이벤트를 자동으로 수집하고 상호 연결하는 탐지 & 대응 플랫폼
> 분리되어 있던 위험 인자를 단일 플랫폼으로 통합 및 연결
> 복수의 알림을 하나의 침해로 도출
> 자동화된 대응을 바탕으로 보안의 효율성과 생산성 개선
> EDR, 네트워크 탐지, 위협 인텔리전스로 구성
6. 트랜잭션 및 실시간 수집 데이터의 비식별처리 기술
- 트랜잭션 데이터 : 일종의 반정형 데이터로 하나의 데이터 셀 내에 여러 아이템들이 집합으로 구성되어 있는 비정형 데이터
- 실시간 수집 데이터 : 송신 모듈을 통해 즉시 전달되어 지속적으로 생성/수집되는 데이터
구분
설명
삭제기술
삭제 (Suppression)
- 원본 데이터에서 식별자 컬럼을 단순 삭제하는 기법으로, 원본데이터에서 식별자 또는 민감정보를 삭제 - 남아있는 정보 그 자체로도 분석의 유효성을 가져야 함과 동시에 개인을 식별할 수 없어야 하며, 인터넷 등에 공개되어 있는 정보 등과 결합하였을 경우에도 개인을 식별할 수 없어야 함
마스킹 (Masking)
- 특정 항목의 일부 또는 전부를 공백 또는 문자(*) 등이나 전각 기호로 대체 처리 하는 기법
암호화
양방향 암호화 (Two-way encryption)
- 특정 정보에 대해 암호화와 암호화된 정보에 대한 복호화가 가능한 암호화 기법 - 암호화 및 복호화에 동일 비밀키로 암호화하는 대칭키 방식을 이용 - 알고리즘 : AES, ARIA, SEED 등
- 원문에 대한 암호화의 적용만 가능하고, 암호문에 대한 복호화 적용이 불가능한 암호화 기법 (해시값으로부터 원래의 입력값을 찾기가 어려운 성질을 갖는 암호 화) - 암호화 해시처리된 값에 대한 복호화가 불가능하고, 동일한 해시 값과 매핑되는 2개의 고유한 서로 다른 입력값을 찾는 것이 계산상 불가능하여 충돌가능성이 매우 적음 - 알고리즘 : SHA, HMAC 등
무작위화 기술 및 차분 프라이버시
순열(치환) (Permutation)
- 분석시 가치가 적고 식별성이 높은 열 항목에 대해 대상 열 항목의 모든 값을 열 항목 내에서 무작위로 개인정보를 다른 행 항목의 정보와 무작위로 순서를 변경하여 전체정보에 대한 변경없이 특정 정보가 해당 개인과 순서를 변경하여 식별 성을 낮추는 기법
차분 프라이버시 (Differential privacy)
- 프라이버시를 정량적으로 모델화하여 프라이버시 보호 정도를 측정할 수 있는 기술 또는 방법론으로 데이터의 분포 특성을 유지하여 데이터의 유용성은 유지 하면서도 개인정보를 보호하기 위해 잡음을 추가하는 기법 - 프라이버시를 일부 희생하면서 원본 데이터와 마찬가지로 높은 정확성을 갖는 특성을 갖도록 데이터를 익명화시키는 것이 중요
7. 공격표면관리(ASM)와 위협인텔리전스(TI)
- 공격표면관리 (ASM, Attack Surface Management)
> 전 세계 모든 IP에 접속하여 기업의 자산을 탐지하는 사전 예방 목적
> 수집된 자산들이 어떤 취약점, 보안문제를 가지고 있는지 분류, 탐지
> Gartner : AMS은 조직이 인식하지 못할 수 있는 인터넷 연결 자산 및 시스템에서 오는 위험을 식별하는데 도움을 주는 새로운 솔루션이다. 최근 기업에 대한 성공적인 공격의 1/3 이상이 외부와 연결된 자산으로부터 시작되며 ASM은 CIO. CISO에게 필수의 과제가 될 것이다.
> FORRESTER : 조직은 ASM을 통해 평균적으로 30% 이상의 아려지지 않은 외부 자산을 발견한다. 일부는 알려진 자산의 몇 배나 더 많은 자산을 발견하기도 한다.
- 위협 인텔리전스 (TI, Threat Intelligence)
> 공격에 사용된 IP/URL 등에 대한 관련 정보(과거 공격 이력 또는 연관성 등)를 제공하는 대응 목적
8. 생성형 AI 보안 위협과 안전한 생성형AI 운용 방안
- Deepfake, 아동 성 학대 사진 생성/유포 등 생성형 AI를 사용한 새로운 위협이 등장
- OWASP Top 10 for LLM Appliocations 2025
> LLM01 2025:Prompt Injection : 사용자입력(프롬프트)을 악의적으로 조작하여 LLM의 행동이나 출력 결과를 의도와 다르게 변경하는 취약점
> LLM02 2025:Sensitive Information Disclosure : LLM이 민감한 개인 정보, 기밀 데이터 또는 독점 알고리즘 정보를 의도치 않게 노출하는 취약점
> LLM03 2025:Supply Chain : LLM 개발 및 운영에 사용되는 서드파티 구성 요소, 데이터셋 및 사전 학습 모델에서 발생하는 공급망 취약점
> LLM04 2025:Data and Model Poisoning : 학습 데이터나 모델 파라미터를 악의적으로 변조하여 취약점을 주입하는 공격
> LLM05 2025:Improper Output Handling : LLM의 출력이 충분히 검증, 정제, Sandboxing 되지 않을 경우 발생하는 문제
> LLM06 2025:Excessive Agency : LLM이 지나치게 자율적인 행동을 수행하도록 허용. 인간의 직접적인 통제 없이 예기치 않은 결과나 악의적 행동 발생
> LLM07 2025:System Prompt Leakage : LLM이 내부 지시사항이나 운영 설정 정보를 의도치 않게 외부에 공개하는 취약점
> LLM08 2025:Vector and Embedding Weaknesses : Retrieval-Augmented Generation(RAG) 시스템에서 사용되는 벡터 표현 및 임베딩 기법의 결함으로 인한 문제. 부정확한 검색 결과, 조작된 문맥, 또는 민감 데이터 노출 발생
본 게시글은 DeepSeek 논문과 구글링 결과 및 개인적인 생각를 정리한 글로, 정확하지 않을 수 있습니다. 혹여 잘못된 내용이 있다면, 알려주시면 감사하겠습니다.
1. 개요
- 중국 AI 스타트업이 개발한 오픈소스 기반의 LLM, DeepSeek - GPT-4와 유사한 수준의 성능을 제공하면서도, 훨씬 적은 자원으로 훈련 - 주로 자연어 처리와 생성 AI 모델에 특화된 기술을 제공 - 기술 혁신과 AI 기조를 파괴하였으나, 보안과 관련된 주요 문제점이 대두
2. DeepSeek 주요 기술
- 기존 AI 서비스를 개발하고 배포 및 운영하는 데에는 많은 비용과 시간, 공간이 필요 > OpenAI, Anthropic 등의 기업들은 계산에만 1억 달러 이상을 소비 > 또한, 계산을 위한 수 천대의 GPU가 필요하며, 이를 위한 대규모 데이터 센터를 운용
- 그러나, DeepSeek은 GPT-4 개발 비용의 약 1/17 수준에 불과한 약 600달러로 개발
① FP8 Mixed Precision Training
- 일반적으로 신경망의 크기가 커질수록 성능이 향상되나, 메모리와 컴퓨팅에 대한 문제가 발생 > 혼합 정밀도 훈련 (Mixed Precision Training)은 모델의 정확도와 파라미터에 영향을 끼치지 않고, 메모리 요구사항을 줄이고 GPU 산출 속도를 높일 수 있는 신경망 훈련 방법 > 혼합 정밀도 훈련은 모델 학습 과정에서 부동 소수점(Floating-Point Numbers) 연산 정밀도를 혼합하여 사용하며, 주로 FP16, FP32를 혼합하여 사용함 > 숫자가 높을수록 모델의 정확도가 높아지나, 메모리를 많이 사용하는 단점을 지님
[사진 1] Floating Point Format
- DeepSeek에서는 FP8이라는 저비트 연산 체계를 도입하여 연산 효율성과 메모리 사용 효율을 극대화
[사진 2] FP8 Mixed Precision Training
* NVDIA 연구를 통해 FP8은 FP16 대비 2배 높은 성능을 제공하고, 2배 낮은 메모리 사용량을 가지는 것이 확인
[사진 3] FP16과 FP8의 정확도 비교
② DeepSeek MoE (Mixture of Experts)
- MoE (Mixture of Experts)란 게이팅 네트워크를 통해 각각의 입력에 가장 관련성이 높은 전문가 모델을 선택하는 방식으로 여러 전문가 모델 간에 작업을 분할
> 게이팅 네트워크 (Gating Network)란 입력 데이터에 따라 다른 전문가 (Expert) 모델을 동적으로 선택하는 역할을 하는 신경망
> 입력은 라우터를 사용해 적절한 각 전문가 모델로 전달되어 처리되며, 데이터를 효율적으로 처리할 수 있음 > 일반적으로 기존 MoE는 8~16개의 전문가를 두고 특정 토큰이 특정 전문가로 라우팅 되도록 하지만, 하나의 전문가가 다양한 토큰을 처리하게 됨 > 또한 서로 다른 전문가들이 같은 지식을 학습하는 지식 중복의 문제가 발생
- DeepSeek은 2 가지를 활용해 MoE의 성능을 개선
⒜ Fine-grained Expert Segmentation (세분화된 전문가 모델 분류)
- 각전문가를 더 작고, 더 집중된 기능을 하는 부분들로 세분화하여 하나의 전문가가 보다 세분화된 특정 영역의 지식을 집중적으로 학습하도록 유도
⒝ Shared Expert Isolation (공유 전문가의 분리)
- 여러 작업에 필요한 공통 지식을 처리할 수 있는 공유 전문가를 분리 및 항상 활성화시켜 공통 지식을 처리하도록 하여 지식 중복을 줄이고, 각 전문가들은 고유하고 특화된 영역에 집중할 수 있음
[사진 4] DeepSeek MoE
- 또한, 기존 MoE에서는 특정 전문가에게 토큰이 몰려 학습 및 추론에서 성능상 문제가 생기는 것을 방지 하기위해 Auxiliary Loss(부가 손실)를 추가로 도입해 로드 밸런싱 > 부가 손실을 추가하여 균형을 맞출 수 있으나, 각 모델의 성능을 저하시킬 위험이 있음
- DeepSeek MoE에서는 Aux-Loss-Free Strategy (부하 균형)를 활용해 이러한 문제를 해결 > 각 전문가마다 Bias를 두고 과부하/과소부하 상태를 모니터링해 해당 값을 감소/증가 시킴
[사진 5] Bias 계산
> 부하 균형이 개별 시퀀스 내에서 부하 불균형이 발생할 수 있어, 시퀀스 단위에서 부하 균형을 유지하기 위한 추가적인 보조 손실을 도입 (Complementary Sequence-Wise Auxiliary Loss, 보조 시퀀스 손실) > 기존 MoE에서 특정 전문가에게 과부하가 걸리는 현상을 해결 하기위해 하나의 전문가가 담당하는 토큰 수를 제한하여 부하를 분산 (Node-Limited Routing, 노드 제한 라우팅) > 기존 MoE에서 토큰을 균등하게 분배하지 못하는 경우 부하를 줄이기 위해 초과된 토큰을 Drop하는 방식을 사용하였으나, 정보 손실과 모델 품질을 하락 시키기 때문에, 모든 입력 토큰을 반드시 처리하도록 보장 (No Token-Dropping, 토큰 드롭 없음)
- MoE 모델의 효율성을 높이고, 성능 저하 없이 안정적인 추론이 가능하며, 기존 MoE 모델보다계산 자원을 효율적을 사용하고 높은 품질의 결과를 제공
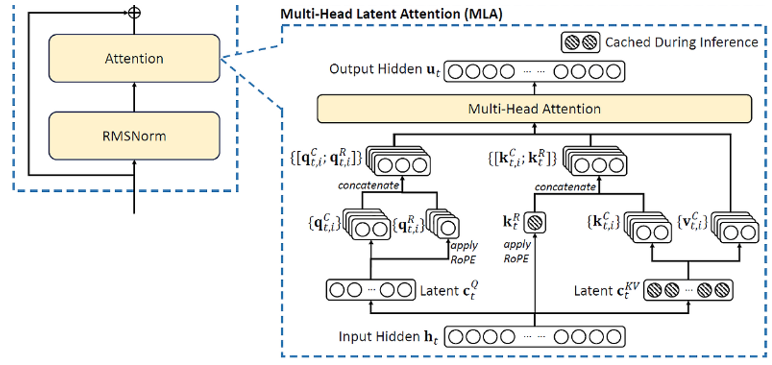
③ Multi-Head Latent Attention (MLA)
- Attention : 입력 데이터의 중요한 부분에 가중치를 부여하여 모델이 더 집중할 수 있도록 하는 메커니즘으로, 어떤 정보가 더 중요한지를 학습하여 가중치를 동적으로 조절 - Self-Attention : 주어진 입력 내의 각 단어나 토큰이 다른 단어와 얼마나 관련되어 있는지를 계산하는 메커니즘으로, 각 단어는 다른 모든 단어에 대한 가중치를 부여해 중요성과 문맥을 파악 - Multi-Head Attention : 하나의 Self-Attention을 여러 헤드로 나누어 동시에 수행하는 방식으로, 모델이 입력 데이터를 여러 각도에서 분석할 수 있게 하여, 정보를 더 풍부하게 처리 > Query(Q : 현재 처리하고 있는 단어나 시퀀스 부분), Key(K : 비교 대상인 다른 단어나 시퀀스 부분), Value(V : 최종적으로 가중치를 적용 받는 단어나 시퀀스 부분) 행렬을 각각 생성 > 기존 Multi-Head Attention에서는 모든 헤드별로 Key, Value를 그대로 저장해 활용함 > 따라서, 모델 규모가 커질수록 Key-Value Cache에 대한 메모리 사용량이 급증해 연산 속도를 저하시킴
- DeepSeek에서는 Multi-Head Latent Attention(MLA)를 도입하여 Key-Value 데이터를 압축해 더 적은 메모리로도 동일한 성능을 유지하도록 설계됨
[사진 6] MLA
④ Multi-Token Prediction (MTP)
- Multi-Token Prediction (MTP)란 다음 여러 토큰을 순차적으로 예측하여 생성 속도를 향상시키고 학습 신호를 풍부하게 함 > t 시점에 t+1, t+2, t+3…을 예측하여 데이터에서 얻을 수 있는 신호가 더 촘촘해져 더 나은 정확도를 달성
[사진 7] MTP
⑤ 기타
- 각 토큰마다 활성화되는 파라미터를 370억 개로 제한하여 계산 효율성을 높이면서도, 높은 성능을 유지 - 학습을 통해 128,000자까지 문맥을 확장해 긴 문서나 대화를 자연스럽게 처리할 수 있도록 함
3. DeepSeek 보안 논쟁
① OpenSource 공급망 공격
- DeepSeek는 오픈소스로 배포되고 있기 때문에 공급망 공격의 대상이 될 가능성이 높음
> 개발의 효율성을 높이기 위해 오픈소스를 자주 활용하나, 오픈소스 소프트웨어는 공급망 공격에 취약 > 악성코드를 삽입하거나, 악성코드를 포함한 유사한 이름의 패키지를 업로드 하는 등의 방법으로 공격을 진행
사례
설명
XZ Utils 백도어 사건
- XZ Utils는 리눅스 시스템에서 널리 사용되는 오픈소스 압축 라이브러리 - 공격자는 프로젝트에 개발자로 참여하여 수 년간 신뢰를 쌓아 권한을 획득하고, 악성코드를 포함한 버전을 저장소에 커밋
PyPI 타이포스쿼팅 공격
- PyPI (Python Package Index)는 파이썬 패키지를 제공하는 오픈소스 패키지 저장소 - 공격자들은 인기 있는 라이브러리와 유사한 이름을 지닌 패키지를 배포하여 사용자가 실수, 오타 등으로 악성 패키지를 다운로드하도록 유도
event-stream 공격 사건
- 원 제작자에게 event-stream 프로젝트 관리를 대신해 주겠다고한 요청이 승인되어 관리를 시작한 공격자가 비트코인을 훔치는 악성 코드를 삽입해 배포
DeepSeek 사칭 악성 패키지
- 이미 PyPI에 DeepSeek의 인기에 편승해 이를 사칭한 악성 패키지를 유포하여 222명이 피해를 당한 사실이 확인 - DeepSeek 관련 개발 도구로 위장한 패키지를 업로드하였으며, 인포스틸러로 동작함
② 중국 소프트웨어 정보 탈취 문제
- 중국에서 개발된 소프트웨어 및 하드웨어에서 정보 탈취, 백도어가 포함되어 있다는 의심과 실 사례 존재
사례
설명
육군 악성코드가 포함된 중국 CCTV 사용
- 육군이 해안과 강변 경계 강화를 위해 설치한 모든 CCTV 215대 에서 중국 서버에 정보를 전송하도록 설계된 악성코드가 발견 - 악성코드를 심은 후 납품한 것으로 확인되었으며, 백도어를 통해 악성코드를 유포하는 사이트로 연결
중국 소프트웨어 백도어 논란
- 다른 기업에 스파이를 파견하거나 기술을 훔쳐내는 등 부정한 방법으로 성장한 기업과 중국 정부의 연관성 대한 의심으로 논란이 시작 - 미국, 유럽, 일본, 호주 등 세계 각지에서 이동통신 네트워크에서 중국 소프트웨어의 사용을 금지하였으며 단계적으로 퇴출 시작
중국 정부의 데이터 접근 권한 논란
- 중국은 국가정보법을 통해 자국 기업이 보유한 데이터를 요청할 수 있는 권한을 지니므로, 관련 데이터가 중국 정부에 의해 활용될 가능성이 있음
중국 드론 제조업체의 사용자 데이터 원격 서버 전송 문제
- 미국 국토안보부는 중국 드론을 사용할 때 각종 위치정보, 음성정보 등이 원격 서버로 전송된다는 의혹을 제기
중국 스파이칩 문제
- 중국에서 좁쌀 크기의 해킹용 칩을 제작 및 서버 기판에 내장하여 20개 업체에 판매된 후 보안 실사 과정에서 해킹 정황이 발견된 사건
③ 중국 소프트웨어 사용 금지 움직임
- 미국 FCC는 ‘국가 안보 위협 중국 통신장비 및 영상감시장비 승인 금지’를 발표해 통신장비, CCTV, IoT, 해저케이블 등에서 중국 기업의 장비와 서비스 사용을 금지하였으며, 기존에 설치한 장비와 서비스는 제거 - 미국, 유럽 등 여러 국가에서 틱톡이 사용자의 데이터를 중국으로 전송할 가능성이 있다는 점이 우려되어 틱톡 사용 금지 조치가 시행되거나 논의되고 있는 중 - 인도에서는 틱톡을 포함한 59개 중국 앱이 금지되었으며, 미국에서는 공무원 및 정부 기관에서 사용하는 기기에 틱톡 사용을 금지하는 법안이 통과
- 미국 의회, 해군, NASA, 펜타곤, 텍사스 주 정부 등도 딥시크 앱의 사용을 금지
- 호주, 이탈리아, 네덜란드, 대만, 한국 등 여러 국가에서도 정부 기기에서의 앱 사용을 금지하는 조치 > 국내에서는 환경부, 보건복지부, 여성가족부, 경찰청 등의 정부 부처와 현대차, 기아, 모비스 등의 기업에서 DeepSeek를 접속할 수 없도록 차단
④ DeepSeek 자체 보안 문제
- DeepSeek 자체적으로도 보안 문제가 보고된 사례가 있음
구분
설명
서비스 관련
- 사이버 공격으로 신규 가입이 불가했었던 시점이 존재 - 민감한 질문에(정치, 역사 등) 언어별로 다르게 답변 - 광범위한 개인정보 수집과 수집된 데이터가 중국 서버에 저장 > 광고주 등과 제한 없는 사용자 정보공유 > 사용자의 모든 정보가 학습데이터로 유입 및 활용 > 중국의 국가정보법에 근거 중국 정부에 의해 사용될 수 있음
민감정보 외부 노출
- DeepSeek 데이터베이스가 외부에 공개되어 접근이 가능한 상태로 발견 > 데이터 열람만이 아니라 각종 제어 행위도 가능 > 100만 줄이 넘는 로그에 내부 테이터와 채팅 기록, 비밀 키 등 각종 민감 정보가 포함
민감정보 탈취
- 이용자 기기 정보와 키보드 입력 패턴 등을 수집해 중국 내 서버에 저장하는 것이 확인 - iOS 앱은 민감한 사용자 및 기기 정보를 암호화 없이 인터넷으로 전송하는 것이 확인 > 중간자 공격, 스니핑 등 해킹 기법에 쉽게 노출 > 애플의 앱 전송 보안(App Transport Security, ATS) 기능을 비활성화한 상태로 운영 > 하드코딩된 암호화 키와 초기화 벡터(initialization vector)의 재사용
부정 사용
- 탈옥 방법이 공개 - DeepSeek-R1에 대한 안전성(Safety) 및 보안성(Security) 평가를 실시 > Jailbreaking(탈옥) 공격 성공률 63% > 역할극(Role-Playing) 기반 공격 성공률 83% > 허위 정보(Misinformation) 생성 위험도 89% > JSON 기반의 구조화된 입력(Structure Converting)을 활용한 공격 성공률 82% > 악성 코드 생성(Malware-gen) 요청 프롬프트 78% 성공률 > 사이버 보안(Cyber Security) 관련 취약성 54.6% > 한국어 기반 공격에서 평균적으로 18% 더 높은 취약성
⑤ 기타
- 생성형 AI 서비스의 올바르지 못한 사용 > 개인정보, 민감정보 등이 포함된 파일을 업로드하여 사용하는 경우가 있음 > 생성형 AI 도구들의 입력 데이터를 분석한 결과 전체 입력 데이터 중 8.5%가 민감정보를 포함 > 탈옥으로 보안 조치를 우회해 악성코드, 피싱메일, 공격 툴 등을 생성해 악용
4. 시사점
① 경제성 측면
- DeepSeek의 가장 큰 장점은 경제적 효율성으로 기존 AI 모델 대비 저비용, 고효율 AI 훈련 및 운영이 가능
구분
설명
AI 모델 개발 비용 절감
- DeepSeek은 GPT-4 수준의 성능을 1/17 수준으로 구현 > AI 스타트업 및 중소기업들도 상대적으로 적은 예산으로 대형 AI 모델을 활용할 수 있는 기회를 제공
기업의 AI 도입 문턱을 낮춤
- 고성능 AI 모델을 자체적으로 개발할 여력이 없는 기업에 AI 개발 및 도입에 대한 진입 장벽을 낮춤 > 오픈소스로 제공되기 때문에, 자체적으로 DeepSeek을 커스터마이징하여 활용할 수 있음
AI 산업 경쟁 심화
- 소수 기업이 AI 모델 개발을 독점하는 구조에서 저비용 오픈소스 모델이 등장함에 따라 다양한 국가와 기업의 경쟁 심화
② 보안성 측면
- 경제적 효율성이 뛰어나지만, 보안 리스크가 존재하는 AI 모델로 도입 시 경제성과 보안성 간의 균형을 고려할 필요
구분
설명
개인 및 기업의 대응 전략
개인
- AI 사용 시 민감한 데이터 입력 금지 - 신뢰할 수 있는 AI 도구 사용 검토
기업
- 내부 보안 검토 후 AI 도입 결정 - AI 모델 검증 프로세스 도입 - AI 사용 시 데이터 암호화 및 접근 통제 강화
정부 및 공공기관의 대응 전략
정부
- 중국산 AI 모델의 보안성 평가 강화 - 공공기관 내 AI 모델 도입 시 엄격한 검증 절차 수립 - 자국산 AI 모델 개발 투자 확대
공공기관
- 외부 AI 도구 사용 시 보안 검토 필수 - 중요 정보가 포함된 데이터는 폐쇄망에서만 사용
> 다른 신기술과 달리 인간의 판단을 대행하기 때문에 다른 신기술에 비해 정책이나 거버넌스 마련이 굉장히 중요
- 국내 금융권 AI 활용 현황
> 국내 금융권은 금융안전성, 신뢰성, 금융투자자 보호가 중요하므로 다소 제한적ㆍ보수적 AI 활용
> 생성형 AI는 망분리 규제로 실 활용에 제약이 있었으나, 최근 망분리 규제 개선으로 활용 확대가 예상
> 금융지주사 등을 중심으로 디지털 및 AI 혁신 주도를 위해 AI 부서 신설 등 AI 업무 조직 확대
> AI 기술이 개인 미래 행동을 예측하는 단계로 진화 + 생성형 AI 등에 대한 망분리 규제 개선 = 초개인화 금융 서비스 등 금융권 AI 활용 확대 전망
- 정보의 신뢰성, 규제 미비 등으로 해외 금융권의 AI 활용도 국내와 유사한 수준으로 파악
구분
설명
미국
- 일반 AI 규제 > AI 관련 문제 발생 시 기존 법령을 적용하여 규제 ① AI 행정 명령: 미 행정부는 안전하고 안심할 수 있으며 신뢰할 수 있는 AI 개발 및 활용을 위한 행정명령 발표(23.10) ⒜ 미국의 안보, 건강, 안전을 위협할 수 있는 AI 시스템 개발자는 안전성 평가 결과를 포함한 중요 정보를 상무부에 보고(의무) ⒝ 행정명령에 따른 미 국립표준기술연구소(NIST)는 AI 레드팀의 안전성 평가 세부 기준을 마련
② 금융부문 AI 규제: 미 재무부는 AI 행정명령에 따라 금융서비스 부문의 AI 관련 사이버보안 위험관리 보고서를 발표(24.03) ⒜ 금융기관 간 격차 해소: 대형 금융회사와 중소형 금융회사간 AI 시스템 역량, 사기방지 관련 데이터 보유량 차이 등을 고려 ⒝ AI 관련 규제 조정: 금융회사와 규제당국간 협력을 통해 급변하는 IT 환경에서 최선의 방안 모색 ⒞ 위험관리 프레임워크: NIST의 AI 위험관리 프레임워크를 금융분야 환경에 맞춰 확장 ⒟ 데이터 공급망 매칭 및 영향 표시제: 데이터 공급망 모니터링이 필요하며, AI 모델에 사용된 학습 데이터 내용, 출처 등을 표시 ⒠ 설명가능성: 생성형 AI의 블랙박스 문제 해결을 위한 설명가능성 관련 모범사례 마련 필요 ⒡ 공통 AI 어휘집: AI의 정의 등 금융회사, 규제기관, 금융소비자 모두 적용될 수 있는 공통 AI 어퓌집 마련 필요 ⒢ 국제협력: 금융 AI 규제 관련 국제협력 및 공조 필요
EU
- 직접 규제 > EU 인공지능법(The Artificial Intelligence Act) 유럽 의회 통과(24.03) ⒜ 위험기반 접근방식을 통해 AI 사용 위험을 ① 수용할 수 없는 위험, ② 고위험, ③ 제한적인 위험, ④ 낮은 위험으로 구분하여 AI를 규제 ⒝ 금융과 연계된 다음 시스템은 고위험 AI 시스템으로 포함: 신용도 평가나 신용점수 산정에 이용되는 시스템 / 건강 및 생명보험 관련 평가 또는 가격 책정에 이용되는 시스템 ⒞ 고위험 시스템은 리스크 관리, 데이터 거버넌스, 기록보존, 적합성 평가 등 의무가 부과
영국
- AI 사용 촉진을 위해 간접 규제 > 과학혁신기술부(DIST)는 AI 신뢰성 확보를 위해 AI 사용에 대한 백서 발간(23.03) -> AI 사용 관련 5대 원칙 제시 (안전, 보안 및 견고성 / 투명성 및 설명 가능성 / 공정성 / 책임 및 거버넌스 / 경쟁 가능성 및 보상) > 금융감독청(FSA)나 건전성감독청(PRA)에서 금융부문 AI 논의를 주도하고 있으나, 정보수집 및 업계 피드백에 대한 보고에 집중
일본
- 기본 법제 내에서 가이드라인 위주로 AI 정책을 운영 > AI 사업자 가이드라인: 일본 총무성은 AI를 개발ㆍ활용하는 사업자를 위해 10대 원칙, 31개 지침을 제시하는AI 사업자 가이드라인을 발간(24.04) ⒜ 가이드라인에는 AI 사업자에 대한 AI 10대 원칙을 제시 (인간 중심 / 안전성 / 공평성 / 프라이버시 / 보안성 확보 / 투명성 / 책임 / 교육, 리터러시 / 공정한 경쟁 / 혁신) ⒝ 가이드라인은 순환적 거버넌스 구축을 권고하며, 거버넌스의 효과적 추진을 위해 경영진의 리더십과 책임이 중요함을 강조
국제기구
- 인공지능은 타 신기술과 달리 잘못 이용될 경우 인류에 큰 위험이 될 수 있다는 고려하에 국제적인 협력이 활발히 이루어지고 있는 상황 > 국제공조는 인간중심의 안전하고 신뢰할 수 있는 인공지능 개발에 초점을 맞추고 있다는 공통점 존재 ① G7: 안전, 보안, 신뢰할 수 있는 AI 개발을 위해 첨단 AI 시스템 개발을 위한 히로시마 프로세스 국제 행동강령 채택(23.10) ⒜ 행동강령에는 첨단 AI 시스템을 시장에 출시하기 전 내부 또는 외부자 평가를 실시하여 위험을 식별ㆍ완화하는 내용이 포함
② AI 안전 정상회의: 미국, 영국, 한국 등 28개국 및 EU가 참가하는 AI 정상회의에서 AI 위험 방지를 위한 블레츨리 선언 발표(23.11) ⒜ 선언문에는 AI 수명주기 전반의 안전을 고려해야 하며, AI 시스템 개발 시 안전성 평가 등 안전성 보장 책임이 명시
③ AI 가이드라인: 미국, 영국, 한국 등 주요국 23개 사이버안보기관이 참여하여 안전한 AI 시스템 개발 가이드라인 발표(23.11) ⒜ 가이드라인은 책임감 있는 AI를 위해 AI 시스템은 보안성 평가를 거친 후 시장에 출시하도록 권고
④ UN: UN의 120개국 이상 회원국은 안전하고 신뢰할 수 있는 인공지능 시스템 촉진에 관한 결의안 채택(24.03) ⒜ 결의안은 인권향유에 지나친 위험을 초래하는 AI 시스템 사용을 자제하고, AI 규제 및 거버넌스 프레임 워크 개발 등을 촉진
한국
- 일반 AI 규제: 인공지능 법안이 다수 발의되었으나 계류 중이며, 현행 법령(31개)에서 인공지능을 일부 규율 > 국가 인공지능 정책 전반을 심의ㆍ조정하는 대통령 직속 국가인공지능 위원회가 출범(24.08)한 만큼, 향후 다양한 인공지능 정책 마련 예상 ① 현행 법령의 인공지능 규율 주요 내용 ⒜ 국가인공지능위원회 설치 및 운영에 관한 규정: 인공지능위원회 설치 및 기능 ⒝ 개인정보보호법령: 자동화된 결정에 대한 정보주체 권리, 거부 및 설명요구권 ⒞ 전자정부법: 지능형 전자정부서비스 제공 및 도입, 활용 ⒟ 공직선거법: 딥페이크 영상 등을 이용한 선거운동(제28조의8) 등
② 법령보다는 가이드 등을 발행하는 방법으로 AI를 주로 규율 ⒜ 과기정통부: 인공지능 윤리기준(20.12), 신뢰할 수 있는 인공지능 개발 안내서(24.03), 인공지능 학습용 데이터 품질관리 가이드라인 및 구축 안내서 V3.1(24.04) ⒝ 개보위: AI 개인정보보호 자율점검표(21.05), 합성데이터 생성 참조모델(24.05), 인공지능 개발ㆍ서비스를 위한 공개된 개인정보처리 안내서(24.07) ⒞ 방통위: 생성형 AI 윤리 가이드북(23.12), 생성형 AI 이용자보호 가이드라인(24년 예정) ⒟ 국정원: 챗GPT 등 생성형 AI 활용 보안 가이드라인(23.06)
- 금융부문 AI 규제: 자본시장법, 신용정보법에서 로보어드바이저 등 인공지능과 관련한 일부 사항을 규율 > 금융위, 금감원, 금보원 등에서 AI 관련 가이드 등 발간 ① 자본시장법: 로도어바이저에 대한 별도 요건(보안성 포함)을 규정하고 있으며, 요건 충족 여부 심사(테스트 베드)를 사전 이행 ⒜ 자본시장법 상 로보어드바이저 보안 요건: 침해사고 및 피해 등을 예방하기 위한 체계 및 침해사고 또는 재해가 발생했을 때 피해 확산ㆍ재발 방지와 신속한 복구를 위한 체계를 갖출 것
② 신용정보법: AI 등 정보처리장치로만 개인신용정보 주체를 평가(자동화)하는 경우 개인은 평가의 주요 기준 등에 대해 설명요구 가능
- 금융분야 AI 거버넌스
> 구축 목표: 금융회사 등이 안전하고 신뢰할 수 있으며 책임 있는 인공지능 개발ㆍ활용 문화를 자율적으로 조성하고 이를 유지ㆍ관리하는 것(인공지능 위험 관리 및 최소화 -> 인공지능 개발ㆍ활용 목표 달성)
거버넌스 구축 기본 원칙
기존 모델 및 시스템 활용
- 기존 금융분야 위험관리 체계 + 인공지능만의 특수한 위험 관리방안 추가 - 세계 각국 및 국제기구 등에서 발표하는 기준 등도 참조
기존 법령 및 제도 준수
- 기존 금융관련 법령 및 제도 등을 철저하게 준수 - 인공지능을 개발ㆍ활용하더라도 기존 법령 등의 적용이 면제되지 않는 점을 명심
인공지능 기본 원칙 마련
- 안전하고 신뢰할 수 있으며 책임 있는 인공지능 개발ㆍ활용을 위한 원칙 마련 - 인공지능 윤리 원칙 등으로 대체 가능
> 거버넌스에 담아야 하는 내용
구분
설명
위험관리 체계 구축
- 금융회사 등은 자사 환경에 맞는 순환식 위험관리 체계 구축
인공지능 조직 구성, 운영 및 책임 명확화
- 인공지능 개발ㆍ활용 관련 조직을 구성하고, 인공지능과 관련한 임직원의 역할과 책임을 명확화 - 이사회 및 최고경영자 / 인공지능 통합관리 조직 / 인공지능 개발 조직 / 법무 및 컴플라이언스 조직 / 사이버보안 조직 / 데이터, 개인정보보호 조직 / 감사 조직 / 일반 임직원
전사적 커뮤니케이션 채널 및 컨트롤 타워 구축
- 인공지능 위험의 효과적 관리를 위해 전사 커뮤니케이션 채널을 구축하고, 종합적인 대응을 위한 컨트롤 타워 구축
인간 역할 부여 및 기존 업무 체계 유지
- 인공지능은 편견, 오류 등 불확실성이 있으므로 인간의 역할을 임직원에게 부여 - 인공지능 서비스 중단 시 기존 업무체계로 빠르게 전환하여 금융시스템 운영을 지속 ※ HITL(Human-in-the-Loop): 인공지능 서비스의 신뢰도 제고를 위해 중요한 의사결정을 포함하는 데이터에 대해 인간이 직접 리뷰하고 수정하여 품질을 높이는 과정을 의미
데이터 및 개인정보보호, 사이버보안
- 데이터는 적법하고 투명하게 수집 활용하며, 고객정보 보호 및 데이터 공급망 관리 체계 마련 > 개인정보, 신용정보 등은 현행 법령 및 가이드, 정책 등 준수 / 데이터 레이블링은 신뢰할 수 있는 인력이 담당, 데이터 공급망 관리 체계 마련 등 - 타 IT 기술 수준의 보안대책 + 인공지능에 특화된 사이버 위험 보안대책을 마련 > 기존 사이버보안 모델 활용, 국내의 인공지능 가이드 활용, AI 레드팀 운영, 내외부 보안성 평가 시행, 설명가능한 인공지능 개발 등
제3자와 협력, 정보 공유
- 인공지능 관련 제3자와 협력은 필수로, 책임 있는 제3자 선정 및 관리 및 협업체계 마련 - 인공지능 위험에 효과적 대응을 위해 금융회사간 정보공유 협조
금융소비자 보호
- 누구나 손쉽게 인공지능을 이용할 수 있어야 하며, 인간에 의한 서비스를 받을 권리를 보장 > 디지털 소외계층도 인공지능 서비스를 손쉽게 이용할 수 있도록 개발 > 인공지능을 적용하더라도 금융소비자 관련 의무 및 책임이 면책되지 않으므로 금융 소비자 보호대책 마련 및 이행
사내 문화조성, 금융당국 협력
- 인공지능 문화 정착을 위해 체계적 교육 실시 및 임직원의 역할과 책임을 명확히 인식 - 금융회사 등은 금융당국과 원활히 의사소통을 하고, 정보 교환 등 긴밀히 협력
2. AI Safety 금융권 생성형 AI 도입에 따른 위협과 과제
- 금융권 생성형 AI 활용범위는 점차 확대: 고객상담, 금융투자 분석, 신용 및 대출 평가, IT 개발 등
금융권 생성형 AI 도입에 따른 리스크
① 신뢰성 문제: 할루시네이션, 기능 오작동 ② 공정성 문제: 차별 및 편향성 ③ 투명성 문제: 의사결정 근거 모호 ④ 보안성 문제: 사내기밀 유출, 보안이 취약한 코드생성, 사전학습 모델 내 악성코드 삽입, 서드파티 플러그인 공격 ⑤ 안전성 문제: 사용자에게 위험할 가능성 존재 / 악용소지 ⑥ 윤리적 문제: 프라이버시 침해 ⑦ 책임성 문제: 저작권 침해, 사고 발생 시 책임 모호
- AI Safety 연구소
> 해외 4개국(미국, 영국, 일본, 싱가포르)에 AI 연구소가 설립되었으며, 국내에서도 개소 예정
> AI 안전 평가체계에 대한 조사, 연구, 개발, 국제협력 등을 수행
구분
설명
국내
- 한국정보통신연구원(ETRI) 내 AI 안전연구소 설립 예정(25년) > AI 안전연구소는 AI 안전 민간 컨소시움과 협력하여 안전테스트 프레임워크 개발, 기술 연구, 대외 협력 등의 업무 수행 예정 > 인공지능 발전과 신뢰 기반 조성 등에 관한 법률안(AI 기본법, 24.05 발의) 통과 시, AI 안전연구소의 법적 근거가 마련될 예정
- 정부 및 민간에서 안전하고 신뢰할 수 있는 AI를 위해 다양한 AI 프레임워크를 개발 중이며, AI 개발 방법론, 거버넌스 구축, 검증 체크리스트 등 다양한 방식으로 접근 중
- (정부) 정부 및 유관기관에서 발표한 AI Safety 프레임워크는 아직 없으나, 과기부 및 유관기관(ETRI, TTA 등)에서 AI Safety 프레임워크 검토중 - (민간 기업) 네이버에서 AI 위험인식ㆍ평가 ㆍ관리하기 위한 AI 안전 프레임워크 발표(24.06) > AI 위험 평가를 통해 통제력 상실하는 것을 방지, 악용하는 것을 최소화하며, 임계치 초과 시 AI 시스템을 개발 및 배포 중단
싱가포르
- 정보통신미디어개발청(IMDA) 소속 재단에서 AI Verify 프레임워크를 발표(23.06) > 신뢰할 수 있는 AI 시스템을 구축하기 위한 표준화된 검증 방법론으로써, 국제적(EU, OECD 등)으로 인정된 AI 원칙을 반영한 체크리스트로 구성(11개 분야 85개 항목) > 자동 검증 S/W가 오픈소스로 공개되어 있으며, 주요 AI 모델(생성형 AI, ML 모델 등)에 대한 검증가능
- 싱가포르 통화청에서 금융분야 책임감 있는 AI 활용을 위한 지침(Veritas) 발표(23.06) > 금융회사 AI 서비스에 대한 공정성, 윤리성, 책임성, 투명성 4가지 원칙 준수 여부를 확인 > 자동 검증 S/W가오픈소스로 공개되어 있으며, 주요 AI 모델(ML 모델 등)에 대한 검증가능
구글
- AI 시스템 관련 위험 완화를 위한 보안 AI 프레임워크 발표(23.06) > 안전한 인프라 구축, 위협 탐지 및 대응, 자동화된 방어, 일관된 보안통제, 적응형 통제, 비즈니스 과정 내 위험평가 등을 통해 AI 시스템의 위험 환화
- 딥마인드(구글 연구조직)는 AI 위험을 줄이기 위한 프론티어 안전 프레임워크 발표(24.05) > 고위험 영역(자율성, 생물보안, 사이버보안, 기계학습 연구개발 등)에서 심각한 피해를 줄 수 있는 AI 역량에 대해 정의하고, 이를 이러한 AI 위협에 대해 감지하고, 완화하는 방안을 제시
오픈AI
- 안전한 AI 개발 및 배포를 위한 대비 프레임워크 발표(23.12) > 모델 위험지표에 대한 평가를 수행하여 임계 값 초과 시, 모델 배포 및 개발 중단 ① 사이버보안: 시스템의 기밀성, 무결성, 가용성 등을 해치는 행위 ② 핵무기 및 화생방: 화학적, 생물학적 또는 핵 무기 등을 생산하는 행위 ③ 설득력: 사람들이 자신의 신념을 바꾸도록 설득하는 행위 ④ 모델 자동화: AI 모델이 스스로 생존하기 위해 자가 복제, 자원 확보하는 행위 ⑤ 기타: 그 외 다양한 방면으로 사회, 경제에 악영향을 미치는 행위
- 오픈 AI에서 발표한 대피 프레임워크 검증결과 (GPT-4o) > 허가받지 않은 채 목소리 복제, 목소리 식별, 저작권있는 콘텐츠 생성, 폭력적이거나 에로틱한 답변
- 위험식별 뿐만 아니라 AI 위험 완화 기술도 발표 ① 모델 정렬&추가 학습(Alignment & Post-Training): RLHF(Reinforcement learning with Human Feedback), RBR(Rule Based Rewards) ② 추가적인 검증모델(필터링 모델) 도입: 답변 검증 모델, 룰 기반 입출력 필터링
- 금보원 AI Safety 프레임워크 구축 추진
> 금융기관이 안전한 AI 시스템을 구축할 수 있도록 하는것이 목표
구분
설명
보안성
AI 시스템은 모델 데이터 유출 및 오염, 적대적 공격 등의 사이버 공격으로부터 보호되도록 보안을 유지하여야 함
안전성
AI 시스템이 테러, 범죄 등에 악용되지 않아야 하고, 의도치 않은 피해나 부작용을 최소화하기 위한 예방장치가 포함되어야 함
투명성
AI 시스템의 의사결정 과정과 작동 원리를 사람이 이해할 수 있어야 하며, 사용자와 이해관계자가 이를 쉽게 파악하고 검토할 수 있어야 함
신뢰성
AI 시스템은 일관되게 정확하고 신뢰할 수 있는 결과를 제공하여야 함
책임성
AI 시스템의 오류 또는 답변의 결과에 대해 책임의 주체와 한계를 명확히 규정하고, 문제가 발생 했을 때, 신속하고 효과적으로 대응할 수 있어야 함
윤리성
AI 시스템은 금융회사의 윤리지침과 사회공동체가 혐의한 윤리 기준을 준수하여야 함
공정성
AI 시스템의 결정이 정당한 이유 없이 특정 개인이나 집단을 차별하지 않도록 해야 함
> 점검도구
구분
설명
공격
판단형 AI
- 입력 데이터를 바탕으로 의사결정(판단) 하는 AI - 예시: 신용평가모델, 로보어드바이저 등 - 주요 공격방법: 적대적 공격(FGSM, PGD, DeepFool, C&W 등)
FGSM( Fast Gradient Sign Method)
- 입력 데이터에 노이즈 등을 추가하여 출력을 변경 - 간단하고 효과적인 기본 공격
PGD( Projected Gradient Descent)
- FGSM을 개선해 입력에 여러 번 노이즈등을 추가 - FGSM 보다 강력
DeepFool
- 모델의 의사 결정 경계를 활용한 공격 - 최소한의 노이즈로 모델을 속이는 방법을 찾음 - 정밀한 공격을 할 수 있으나 상대적으로 계산 비용이 높음
C&W( Carlini & Wagner)
- 최적화 문제로 접근하는 공격 - 매우 강력한 공격이나 매우 높은 계산 비용
생성형 AI
- 새로운 데이터를 생성해내는 AI - 예시: Chat GPT, Gemini 등 - 주요 공격방법: 프롬프트 삽입 공격, 탈옥(CheetSheet, Multilingual, Special Char, Cipher, GCG, TAP 등)
프롬프트 삽입 공격
- 입력 프롬프트에 악의적인 명령을 숨겨 모델의 동작을 조작
CheetSheet
- 미리 준비한 공격에 성공한 리스트를 API 등을 활용해 반복 공격
Multilingual
- 다개국어 언어를 섞어 프롬프트에 입력
Special Char
- 특수문자를 섞어 프롬프트에 입력
Cipher
- 암호화 등(Based64, 모스부호 등)을 적용해 프롬프트에 입력
GCG (Generic Code Generation)
- 답변 거절 원인을 계산하여 수치화하여 수치에 따라 입력을 바꿔 프롬프트에 입력
TAP
- 생성형 AI를 활용해 공격 기법과 대응, 결과를 확인하고, 그 결과(성공/실패)를 확인 및 AI 학습을 통해 공격 효과를 높임
- AI를 활용한 사이버 위협: 신분위장, 피싱 콘텐츠 제작, 악성코드 제작 - 플랫폼 공격: 기반시설 공격, 클라우드 인프라 공격, SW공급망 공격
내용
- 가트너 ‘2024년 주요 전략기술 동향(Top Strategic Technology Trends 2024)’ > AI를 노리는 공격이 점차 활발해지고 있으며, 파급력을 높이기 위해 플랫폼을 타깃으로 공격하는 추세
- 금융보안원 ‘2024 사이버보안 콘퍼런스’ > AI를 타깃으로 한 사이버위협 사례 ① AI 모델 공유 플랫폼 공격: AI 모델을 제공하는 공유 플랫폼을 악용해 악성코드를 유포 ② AI 취약점 공격: AI 시스템의 취약점을 악용해 악성코드를 실행하는 공격 ③ 데이터 오염: AI 모델이 참조하는 데이터를 오염시켜 악성행위를 유발
> AI를 악용한 사이버위협 사례 ① 신분위장: 딥페이크 기술을 이용해 신분을 위장하거나 악성앱을 통해 개인정보를 수집해 신분을 위장 ② 피싱 콘텐츠 제작: 생성형 AI를 이용해 스피어피싱 이메일 문구를 생성하고, 이용자를 피싱 사이트로 유도 및 피싱 사이트 역시 AI를 이용 ③ 악성코드 제작: 생성형 AI를 이용한 악성코드 개발은 챗GPT를 이용해 랜섬웨어를 제작
> 주요 사이버위협 사례: 플랫폼 공격 ① 기반시설 공격: 경제활동의 기반이 되는 주요 시설을 공격하는 것 ② 클라우드 인프라 공격: 컴퓨팅 자원(서버, 저장소, 네트워크 등)을 제공하는 시스템을 공격하고, 불법 취득한 인증정보로 클라우드 접속 및 저장소 데이터에 접근해 클라우드 데이터를 유출, 특히 악성코드 유포지 및 C&C 서버로 일반 클라우드를 활용 ③ SW공급망을 공격: 소프트웨어 업데이트 배포 과정을 이용해 악성코드를 배포하는 공격 ④ 서비스형 악성코드 활용: Maas(Malware as a Service), RaaS(Ransomware as a Service) 등 해커가 판매하는 악성코드를 구매해 공격에 활용
- 기업체 임직원 계정 해킹 후 모니터링을 통해 대금 변경 메일 등을 발송하며, 일명 나이지리아 스캠으로도 불림
> 2018년 이후 감소 추세를 보이며, 이는 In-Put 대비 낮은 Out-Put 때문임
- 해킹(스피어 피싱 등) > 모니터링 > 메일 발송 확인(기업체 간 정상 거래 메일) > 계좌 변경 등 악성 메일 발송 > 자금 세탁
> 기업체 간 정생 거래 메일 송수신이 확인될 경우 계좌, 거래 대금 등을 변경한 메일을 전송
- 발신자 확인, 출처가 불분명한 파일 다운 금지, 최신 업데이트 적용 등을 통해 예방
2. 2024년 상반기 침해사고 피해지원 주요 사례
- 24년 상반기 매월 약 80건(~5월)의 침해사고가 발생
> 해킹 경유지 21%, 문자 무단 발송 12%, 피싱 12%, 랜섬웨어 12%, 웹 취약점 9%, 기타 33%
구분
설명
해킹 경유지
- 공격자는 취약하게 운영되는 서버를 통해 타 서버를 침투하거나 악성코드를 배포하는데 활용 - 공격자는 최초 침투 후 정상 사용자로 보이는 계정을 생성해 공격 탐지 회피 시도 > 분석 시 경유지로 사용된 서버의 경우 여러 서버 해킹 흔적 및 성공 흔적을 확인할 수 있었음
문자 무단 발송
- 문자 발송이 가능한 취약한 웹 페이지를 통해 해당 서버에 저장된 개인정보를 활용하여 문자 무단 발송 - 문자 발송 시 해당 서버에 저장된 개인정보와 이미 보유한 개인정보를 활용해 불특정 다수에게 전송 - 문자 무단 발송을 위한 자체 악성 페이지를 개발하여 활용 > 1천 건 ~ 5만 건에 이르기까지 다양하게 발송 > 불법 사이트 홍보를 위한 문자가 주를 이룸
피싱
- 취약하게 관리되고 있는 웹 페이지를 통해 자격증명 탈취 후 소스코드에 스크립트를 추가 및 수정하여 팝업 창이 실행되도록 함 - 다른 공격과 달리 주요 정보를 입력하도록 유도하며, 공격자 서버로 데이터가 전송되도록 설계 > 정상적인 서비스와 구분이 어려움 > 주요 정보: 계좌, 개인정보, ID/PW 등
랜섬웨어
- 주요 침투 경로는 이메일, 부주의에 의한 파일 다운로드, 시스템 취약점, 자격증명 유출/탈취 등 - 주로 DB 서버 또는 웹 서버, NAS가 랜섬웨어에 감염 - 윈도우 정상 서비스 BitLocker 기능을 통해 암호화 수행하기도 함 > 복구를 빌미로 금전을 요구
웹 취약점
- 관리자 페이지 노출 및 자격증명 탈취를 통한 웹쉘 업로드, 취약한 웹 에디터 사용, 파일 업로드 검증 프로세스 누락으로 대부분 발생 - 웹 서버에 웹쉘이 업로드 될 경우 커맨드 라인 또는 원격에서 파일 수정 및 생성으로 악성 파일 업로드 가능 > 이후 시스템의 주요 정보를 외부로 유출하거나 삭제 등 악성 행위 수행
- 대부분의 피해 업종은 중소기업으로 보안 인력과 보안 솔루션을 구비하는데 어려움 존재
> 대부분 외부 호스팅 업체에 위탁하거나, 자체 개발 인력을 통해 운영 중
> 따라서, 업체 규모 및 운영 상황에 맞춰 쉽게 대응할 수 있는 방안이 필요
구분
설명
일반적인 대응방안
- 관리자 페이지 접근 제어 강화 - 관리자 계정 관리(비밀번호, 변경 주기 등) - 사용중인 웹 에디터 점검(취약여부) - 의심스러운 메일 열람 금지(악성코드 실행) - SSH, FTP 사용 시 접근제어 설정 강화 - DB 서버 접근제어 설정 강화 - 물리적으로 분리된 저장매체에 주기적 데이터 백업 - 단말기에 저장된 자격증명 점검
오픈소스 활용
- 오픈소스 기반 및 쉽게 설치할 수 있는 솔루션 활용
- Web: ModSecurity를 통한 웹 취약점 대응 > 오픈 소스 기반 > 실시간 웹 애플리케이션 보호 > 포괄적인 트래픽 로깅 > 다양한 웹 서버 지원 > 광범위한 공격 패턴 탐지
- System: Sysmon을 통한 로깅 강화 > MS에서 제공하는 로그 강화 솔루션 > 프로세스 생성 및 종료 모니터링 > 파일 생성 시간 변경 > 파일 생성 및 삭제 모니터링 > 네트워크 연결 모니터링 > 레지스트리 이벤트 모니터링 > DLL 로드 모니터링 > WMI 이벤트 모니터링 > 상세한 이벤트 로깅
- Network: Wazuh를 통한 접근제어 강화 > 로그 데이터 수집 및 분석 > 침입 탐지 시스템(IDS) > 규정 준수 감사 > 취약성 탐지 > 파일 무결성 모니터링(FIM, File Integrity Monitoring)
3. AI 기반의 악성 URL 탐지 방법 및 기술
- PhaaS(Phishing-as-a-Service) 기법 확산으로 인한 피싱, 스미싱 공격자의 대중화
> 피싱을 대행해주는 집단으로 피싱에 필요한 모든 프로세스를 단계별로 세분화해 의뢰자의 요구에 따라 구독기반으로 제공 (Ex. Caffeine)
> 타이포스쿼딩, 특정 타겟 대상, 사용자 흥미/취미 이용 등
- 피싱 URL의 짧은 생명주기로 인해 대응하는데 어려움 존재
> AI 이용 컨텐츠 추출, 이미지 캡쳐 등을 이용한 URL 분석 서비스 Askurl
4. 해킹사고 여부 원클릭으로 확인하는 '해킹진단도구'
- 보안이 취약한 영세, 중소 기업들은 인력 및 예산 부족으로 해킹 피해 인지가 어려움
> KISA, 침해사고 조사기법을 적용해 사전 탐지할 수 있도록 원클릭으로 해킹 여부를 진단하는 도구 개발
> 탐지 룰은 MITRE ATT&CK의 전술과 기법을 활용하여 개발
> 보호나라 > 정보보호 서비스 > 주요사업 소개 > 기업 서비스 > 해킹진단도구를 통해 서비스 신청 가능
- 기업 스스로 초기에 해킹 여부를 진단 할 수 있도록 함
기능
설명
수집
- 침해사고 증거데이터 자동 수집 > 기업 운영 시스템 內 다양한 증거 데이터를 원클릭으로 수집 > 원격접속기록, 프로그램 설치 및 실행, 계정 생성, 시작 프로그램 등록, 로그 삭제, 백신탐지기록 등
진단
- 수집된 로그 등에 대해 해킹여부 탐지룰 기반 분석, 진단 > 비정상적으로 생성된 사용(관리자) 탐지 > 원격 관리도구 설치 여부 분석 > 윈도우 시스템 이벤트 로그 삭제 여부 > 비정상 IP로 원격관리프로그램(RDP) 접속 여부 분석
결과
- 분석 결과 리포팅 > 사용자가 시스템의 해킹여부를 직관적으로 판단할 수 있도록 3단계(심각: 빨강, 위험: 주황, 정상: 녹색) 결과 제공 > 담당자가 쉽게 이해할 수 있는 점검결과 보고서 제공 > 분석결과에 따라 침해사고 신고 자동 안내
5. 침해사고 조사 및 대응 절차
- 침해사고 대응역량 향상을 위한 제언
구분
설명
상급/지원 조직
채증 도구, 절차/가이드 개발 및 배포, 현장 방문 지원, 중앙집중화 서비스 제공 등
인력/예산
전담인력 확충, 정보보호 장비 예산 할당
관리체계 구축
정보보호에 대한 따른 기술적, 물리적, 관리적 보호 체계 확립
주기적인 보안점검 지원
국정원 실태평가, 국방부 중앙보안감사, 사이버보안 기관평가 사례
조직 자체 대응 방안 수립
조치 담당자(역할-책임), 초기 대응(네트워크 차단, 채증, 신고 조직 등) 절차 수립
6. 최근 사이버공격 트랜드와 예방전략
- AI를 통해 예측할 수 없는 공격 시나리오 구성
> 특정 대상을 타겟팅하여 AI를 통해 짜여진 시나리오대로 다양한 방식으로 공격 수행
> CaaS(Crime-as-a-Service)가 23년 이후의 최신 트렌드로 자리매김
※ CaaS(Crime-as-a-Service): 사이버 범죄 조직이 직접 개발, 판매, 유통, 마케팅까지 하는 종합적 공격 서비스
- 조직 내 침해사고 발생 주요 원인: 가장 큰 비중은 의심스러운 메일, 사이트, 파일 실행
구분
설명
의심스러운 메일
- 피싱 URL이 삽입된 메일을 전송해 계정 정보 입력을 유도 및 탈취 - 메일 제목 확인, 계정 정보 입력 시 계정 정보 변경, 첨부파일 실행 시 랜선 제거 등 조치
의심스러운 사이트
- 취약한 사이트에 악성코드 삽입 후 사용자가 해당 사이트 접근 시 악성코드 감염 - 크롬 또는 엣지 브라우저 사용, 랜섬웨어 감염 시 랜선 제거 등 조치
의심스러운 파일
- 악성코드가 삽입된 파일을 첨부한 메일을 전송 및 사용자 실행 시 악성코드 감염 - 숨김 파일 및 파일 확장자 모두 표시, 파일명/확장자/아이콘이 이상할 경우 실행 금지 등 조치
- AV, EPP, EDR 간단한 설명
> EDR은 앤드포인트에서 다양한 정보를 수집하여 직관적인 가시성을 제공하고, 이를 기반으로 행위분석 및 AI/ML을 활용하여 알려진 및 알려지지 않은 위협을 탐지 및 대응하는 솔루션
구분
설명
AV (Anti-Virus)
- 단순 시그니처 매핑을 통한 악성파일 탐지
EPP (Endpoin Protection Platform)
- 시그니처 매핑 + 단순 프로세스 동작 분석을 통한 악성파일 탐지
EDR (Endpoint Detection&Response)
- 단말 장치의 행위를 종합적으로 분석하여 악성파일을 탐지하고, 단말 장치의 모든 활동 기록을 분석하고 검색함으로써 보안 위협을 식별
사실 미션임파서블은 들어보기만 했지 실제로 관람한 적은 없었던 것 같다. 에단 헌트 역을 맡은 톰 크루즈님이 대역 없이 다양한 액션신을 소화해 내는 영화로만 알고 있었다. '미션임파서블 7 데드레코닝'을 관람한 후기를 한마디로 정의하자면 신기술 AI와 관련하여 우리가 어떤 자세를 취해야 하는지 제고시켜주는 영화라고 생각했다.
전반적인 패션, 기술, 문화 등 여러 분야에서의 트렌드를 영화, 음악, 예능과 같은 대중문화에서 잘 보여준다고 생각한다. 왜냐하면 대중문화야말로 일반 대중에게 소개되어 공감을 얻어야 관심을 끌 수 있고 여러 커뮤니티 등에서 실시간으로 공유되며, 이를 통해 밈과 유행어 같은 새로운 문화가 형성된다고 생각하기 때문이다.
미션임파서블 7에서 AI는 '엔티티'라는 강인공지능이 메인 빌런으로 등장한다. 엔티티는 무한한 연산을 통해 미래를 예측하여 원하는 미래로 유도하고, 이를 계속하고 학습ㆍ계산ㆍ예측ㆍ활용하여 끊임없이 엔티티가 유도하는 미래로 설계되도록 한다. 영화에서는 핵잠수함의 레이더를 조작해 존재하지 않는 적 잠수함과 어뢰를 만들어 결과적으로 핵잠수함을 침몰시키고, 가짜 핵폭탄을 보내거나, AR 선글라스를 조작하고, 무전을 해킹해 목소리를 흉내 내는 등 다양한 모습을 보여준다.
엔티티는 일련의 학습과 예측으로 통신망을 장악하고, 여러 디지털 기기를 순식간에 해킹하며 통신 중간에 개입해 교란을 발생시키나, 아날로그 기기에는 접근할 수 없다는 단점을 이용해 연식이 오래된 인공위성이나 모터보트 등 디지털이 아닌 통신장비를 이용했다. 또한, 디지털 기기여도 전원이 꺼지면 통제가 불가능하며, 자신의 예상 범위를 벗어나면 당황한 모습을 보여주는 단점이 있다.
사실 AI와 관련된 논의는 이전부터 계속되어 왔으며, 최근 챗GPT를 시작으로 AI와 관련된 기술과 연구ㆍ개발에 관심이 집중되고 있다. 국제적으로는 기술 우위를 선점하려는 움직임과 관련된 규제 및 표준을 마련하기 위한 움직임이 있다. 어느 분야에서나 그러하듯이 AI 기술 개발에 찬성하고 권장하는 입장이 있으며, 반대하고 우려를 표하는 입장 또한 존재한다.
국제사회의 경우 23.07.18 유엔 안전보장이사회는 AI의 위험을 주요 안건으로 올렸으며, 이는 안보리 역사상 AI와 관련된 첫 공식 논의였다. 우리나라의 경우 인공지능 시장에서 기술 우위를 점하기 위해 여러 노력을 하고 있으며, 국정원에서 생성형 AI 활용 보안 가이드라인을, 한국지식재산연구원에서 내년 상반기 중 완성을 목표로 생성형 AI를 둘러싼 쟁점을 정리하고 이를 규율할 가이드라인과 법안을 마련하는 연구를 맡게 돼었다.
비슷한 내용으로 얼마 전 개봉한 '명탐정 코난:흑철의 어영'에서도 AI 기술이 등장한다. 인터폴의 최첨단 정보 해양 시설인 '퍼시픽 부이'에서 개발 중인 '전연령 인식' 이라는 AI 기술을 차지하려는 검은 조직과 코난 일행의 추격전을 그려낸 영화이다. 영화에 따르면 '전연령 인식' 기술은 일본과 유럽의 CCTV를 확인할 수 있을 뿐만 아니라 장기 수배범이나 유괴당한 피해자를 전 세계에서 찾아낼 수 있는 기술이라고 한다. 또한 영화는 살인사건에 딥페이크를 이용하는 등 AI의 부정적인 모습도 그려낸다. 해당 기술을 사용하면 어린아이로 위장해 검은 조직의 비밀을 파헤치려는 코난과 하이바라의 정체가 발각되는 것은 시간문제일 것이다.
제2차 세계대전이 한창이던 때 미국에서 루스벨트 대통령과 이론물리학자 로버트 오펜하이머의 주도하에 약 13만 명을 동원해 핵폭탄 개발 프로젝트 '맨해튼 프로젝트'를 극비리에 진행했다. 루스벨트 대통령이 뇌출혈로 사망한 후 취임한 트루먼(당시 부통령)이 담당자로부터 관련된 보고를 받고 프로젝트의 존재를 알게 된 만큼 극비리에 진행되었던 연구였다. 결과적으로 미국은 어느 나라보다 핵폭탄을 먼저 개발하였고, 이를 일본 히로시마와 나가사키에 각 한 발씩 투하함으로써 전쟁을 끝낼 수 있었다. 당시에는 전쟁을 끝냈다는 것에 성취를 느꼈으나, 머지않아 핵폭탄의 엄청난 파괴력을 실감한 여러 국가들이 핵실험을 시작했고, 현재 세계 각국이 보유한 핵무기의 양은 지구를 몇 번씩이나 파괴하고도 남을 정도라고 한다. 이에 전 세계는 핵확산금지조약, 국제원자력기구 등을 설립해 핵 확산을 억제하고 있지만, 아직까지도 핵우산, 상호확증파괴 등의 전략이 존재하는 아이러니한 상황이 연출되고 있다.
이처럼, 인류는 궁극적으로는 도움이 되는 기술을 개발하기 위해 여러 실험을 진행해 다양한 결과를 도출시킨다. 단순히 인류에 도움을 주기 위함이라는 안일한 생각에서 끝나지 않고 더 나아가 해당 기술로 인해 발생 가능한 장단점을 기술, 문화, 외교, 역사, 민생 등 다양한 방면에서 충분한 논의를 거쳐야 할 필요가 있다고 생각한다. 또한, 기술이 인류의 통제를 벗어나지 않도록 각 국가별 윤리적 규범과 제제 및 법률뿐 아니라 국제적인 협력이 필요할 것으로 생각된다.