
본 게시글은 DeepSeek 논문과 구글링 결과 및 개인적인 생각를 정리한 글로, 정확하지 않을 수 있습니다.
혹여 잘못된 내용이 있다면, 알려주시면 감사하겠습니다.
1. 개요

- 중국 AI 스타트업이 개발한 오픈소스 기반의 LLM, DeepSeek
- GPT-4와 유사한 수준의 성능을 제공하면서도, 훨씬 적은 자원으로 훈련
- 주로 자연어 처리와 생성 AI 모델에 특화된 기술을 제공
- 기술 혁신과 AI 기조를 파괴하였으나, 보안과 관련된 주요 문제점이 대두
2. DeepSeek 주요 기술
- 기존 AI 서비스를 개발하고 배포 및 운영하는 데에는 많은 비용과 시간, 공간이 필요
> OpenAI, Anthropic 등의 기업들은 계산에만 1억 달러 이상을 소비
> 또한, 계산을 위한 수 천대의 GPU가 필요하며, 이를 위한 대규모 데이터 센터를 운용
- 그러나, DeepSeek은 GPT-4 개발 비용의 약 1/17 수준에 불과한 약 600달러로 개발
① FP8 Mixed Precision Training
- 일반적으로 신경망의 크기가 커질수록 성능이 향상되나, 메모리와 컴퓨팅에 대한 문제가 발생
> 혼합 정밀도 훈련 (Mixed Precision Training)은 모델의 정확도와 파라미터에 영향을 끼치지 않고, 메모리 요구사항을 줄이고 GPU 산출 속도를 높일 수 있는 신경망 훈련 방법
> 혼합 정밀도 훈련은 모델 학습 과정에서 부동 소수점(Floating-Point Numbers) 연산 정밀도를 혼합하여 사용하며, 주로 FP16, FP32를 혼합하여 사용함
> 숫자가 높을수록 모델의 정확도가 높아지나, 메모리를 많이 사용하는 단점을 지님

- DeepSeek에서는 FP8이라는 저비트 연산 체계를 도입하여 연산 효율성과 메모리 사용 효율을 극대화

* NVDIA 연구를 통해 FP8은 FP16 대비 2배 높은 성능을 제공하고, 2배 낮은 메모리 사용량을 가지는 것이 확인

② DeepSeek MoE (Mixture of Experts)
- MoE (Mixture of Experts)란 게이팅 네트워크를 통해 각각의 입력에 가장 관련성이 높은 전문가 모델을 선택하는 방식으로 여러 전문가 모델 간에 작업을 분할
> 게이팅 네트워크 (Gating Network)란 입력 데이터에 따라 다른 전문가 (Expert) 모델을 동적으로 선택하는 역할을 하는 신경망
> 입력은 라우터를 사용해 적절한 각 전문가 모델로 전달되어 처리되며, 데이터를 효율적으로 처리할 수 있음
> 일반적으로 기존 MoE는 8~16개의 전문가를 두고 특정 토큰이 특정 전문가로 라우팅 되도록 하지만, 하나의 전문가가 다양한 토큰을 처리하게 됨
> 또한 서로 다른 전문가들이 같은 지식을 학습하는 지식 중복의 문제가 발생
- DeepSeek은 2 가지를 활용해 MoE의 성능을 개선
⒜ Fine-grained Expert Segmentation (세분화된 전문가 모델 분류)
- 각 전문가를 더 작고, 더 집중된 기능을 하는 부분들로 세분화하여 하나의 전문가가 보다 세분화된 특정 영역의 지식을 집중적으로 학습하도록 유도
⒝ Shared Expert Isolation (공유 전문가의 분리)
- 여러 작업에 필요한 공통 지식을 처리할 수 있는 공유 전문가를 분리 및 항상 활성화시켜 공통 지식을 처리하도록 하여 지식 중복을 줄이고, 각 전문가들은 고유하고 특화된 영역에 집중할 수 있음

- 또한, 기존 MoE에서는 특정 전문가에게 토큰이 몰려 학습 및 추론에서 성능상 문제가 생기는 것을 방지 하기위해 Auxiliary Loss(부가 손실)를 추가로 도입해 로드 밸런싱
> 부가 손실을 추가하여 균형을 맞출 수 있으나, 각 모델의 성능을 저하시킬 위험이 있음
- DeepSeek MoE에서는 Aux-Loss-Free Strategy (부하 균형)를 활용해 이러한 문제를 해결
> 각 전문가마다 Bias를 두고 과부하/과소부하 상태를 모니터링해 해당 값을 감소/증가 시킴

> 부하 균형이 개별 시퀀스 내에서 부하 불균형이 발생할 수 있어, 시퀀스 단위에서 부하 균형을 유지하기 위한 추가적인 보조 손실을 도입 (Complementary Sequence-Wise Auxiliary Loss, 보조 시퀀스 손실)
> 기존 MoE에서 특정 전문가에게 과부하가 걸리는 현상을 해결 하기위해 하나의 전문가가 담당하는 토큰 수를 제한하여 부하를 분산 (Node-Limited Routing, 노드 제한 라우팅)
> 기존 MoE에서 토큰을 균등하게 분배하지 못하는 경우 부하를 줄이기 위해 초과된 토큰을 Drop하는 방식을 사용하였으나, 정보 손실과 모델 품질을 하락 시키기 때문에, 모든 입력 토큰을 반드시 처리하도록 보장 (No Token-Dropping, 토큰 드롭 없음)
- MoE 모델의 효율성을 높이고, 성능 저하 없이 안정적인 추론이 가능하며, 기존 MoE 모델보다계산 자원을 효율적을 사용하고 높은 품질의 결과를 제공
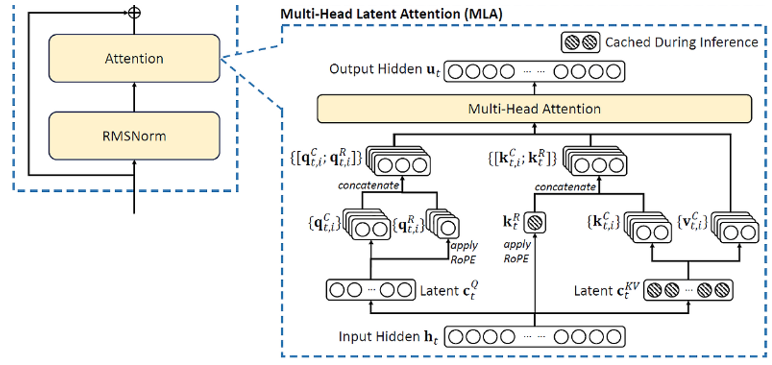
③ Multi-Head Latent Attention (MLA)
- Attention : 입력 데이터의 중요한 부분에 가중치를 부여하여 모델이 더 집중할 수 있도록 하는 메커니즘으로, 어떤 정보가 더 중요한지를 학습하여 가중치를 동적으로 조절
- Self-Attention : 주어진 입력 내의 각 단어나 토큰이 다른 단어와 얼마나 관련되어 있는지를 계산하는 메커니즘으로, 각 단어는 다른 모든 단어에 대한 가중치를 부여해 중요성과 문맥을 파악
- Multi-Head Attention : 하나의 Self-Attention을 여러 헤드로 나누어 동시에 수행하는 방식으로, 모델이 입력 데이터를 여러 각도에서 분석할 수 있게 하여, 정보를 더 풍부하게 처리
> Query(Q : 현재 처리하고 있는 단어나 시퀀스 부분), Key(K : 비교 대상인 다른 단어나 시퀀스 부분), Value(V : 최종적으로 가중치를 적용 받는 단어나 시퀀스 부분) 행렬을 각각 생성
> 기존 Multi-Head Attention에서는 모든 헤드별로 Key, Value를 그대로 저장해 활용함
> 따라서, 모델 규모가 커질수록 Key-Value Cache에 대한 메모리 사용량이 급증해 연산 속도를 저하시킴
- DeepSeek에서는 Multi-Head Latent Attention(MLA)를 도입하여 Key-Value 데이터를 압축해 더 적은 메모리로도 동일한 성능을 유지하도록 설계됨
④ Multi-Token Prediction (MTP)
- Multi-Token Prediction (MTP)란 다음 여러 토큰을 순차적으로 예측하여 생성 속도를 향상시키고 학습 신호를 풍부하게 함
> t 시점에 t+1, t+2, t+3…을 예측하여 데이터에서 얻을 수 있는 신호가 더 촘촘해져 더 나은 정확도를 달성

⑤ 기타
- 각 토큰마다 활성화되는 파라미터를 370억 개로 제한하여 계산 효율성을 높이면서도, 높은 성능을 유지
- 학습을 통해 128,000자까지 문맥을 확장해 긴 문서나 대화를 자연스럽게 처리할 수 있도록 함
3. DeepSeek 보안 논쟁
① OpenSource 공급망 공격
- DeepSeek는 오픈소스로 배포되고 있기 때문에 공급망 공격의 대상이 될 가능성이 높음
> 개발의 효율성을 높이기 위해 오픈소스를 자주 활용하나, 오픈소스 소프트웨어는 공급망 공격에 취약
> 악성코드를 삽입하거나, 악성코드를 포함한 유사한 이름의 패키지를 업로드 하는 등의 방법으로 공격을 진행
| 사례 | 설명 |
| XZ Utils 백도어 사건 | - XZ Utils는 리눅스 시스템에서 널리 사용되는 오픈소스 압축 라이브러리 - 공격자는 프로젝트에 개발자로 참여하여 수 년간 신뢰를 쌓아 권한을 획득하고, 악성코드를 포함한 버전을 저장소에 커밋 |
| PyPI 타이포스쿼팅 공격 | - PyPI (Python Package Index)는 파이썬 패키지를 제공하는 오픈소스 패키지 저장소 - 공격자들은 인기 있는 라이브러리와 유사한 이름을 지닌 패키지를 배포하여 사용자가 실수, 오타 등으로 악성 패키지를 다운로드하도록 유도 |
| event-stream 공격 사건 | - 원 제작자에게 event-stream 프로젝트 관리를 대신해 주겠다고한 요청이 승인되어 관리를 시작한 공격자가 비트코인을 훔치는 악성 코드를 삽입해 배포 |
| DeepSeek 사칭 악성 패키지 | - 이미 PyPI에 DeepSeek의 인기에 편승해 이를 사칭한 악성 패키지를 유포하여 222명이 피해를 당한 사실이 확인 - DeepSeek 관련 개발 도구로 위장한 패키지를 업로드하였으며, 인포스틸러로 동작함 |
② 중국 소프트웨어 정보 탈취 문제
- 중국에서 개발된 소프트웨어 및 하드웨어에서 정보 탈취, 백도어가 포함되어 있다는 의심과 실 사례 존재
| 사례 | 설명 |
| 육군 악성코드가 포함된 중국 CCTV 사용 |
- 육군이 해안과 강변 경계 강화를 위해 설치한 모든 CCTV 215대 에서 중국 서버에 정보를 전송하도록 설계된 악성코드가 발견 - 악성코드를 심은 후 납품한 것으로 확인되었으며, 백도어를 통해 악성코드를 유포하는 사이트로 연결 |
| 중국 소프트웨어 백도어 논란 | - 다른 기업에 스파이를 파견하거나 기술을 훔쳐내는 등 부정한 방법으로 성장한 기업과 중국 정부의 연관성 대한 의심으로 논란이 시작 - 미국, 유럽, 일본, 호주 등 세계 각지에서 이동통신 네트워크에서 중국 소프트웨어의 사용을 금지하였으며 단계적으로 퇴출 시작 |
| 중국 정부의 데이터 접근 권한 논란 | - 중국은 국가정보법을 통해 자국 기업이 보유한 데이터를 요청할 수 있는 권한을 지니므로, 관련 데이터가 중국 정부에 의해 활용될 가능성이 있음 |
| 중국 드론 제조업체의 사용자 데이터 원격 서버 전송 문제 |
- 미국 국토안보부는 중국 드론을 사용할 때 각종 위치정보, 음성정보 등이 원격 서버로 전송된다는 의혹을 제기 |
| 중국 스파이칩 문제 | - 중국에서 좁쌀 크기의 해킹용 칩을 제작 및 서버 기판에 내장하여 20개 업체에 판매된 후 보안 실사 과정에서 해킹 정황이 발견된 사건 |
③ 중국 소프트웨어 사용 금지 움직임
- 미국 FCC는 ‘국가 안보 위협 중국 통신장비 및 영상감시장비 승인 금지’를 발표해 통신장비, CCTV, IoT, 해저케이블 등에서 중국 기업의 장비와 서비스 사용을 금지하였으며, 기존에 설치한 장비와 서비스는 제거
- 미국, 유럽 등 여러 국가에서 틱톡이 사용자의 데이터를 중국으로 전송할 가능성이 있다는 점이 우려되어 틱톡 사용 금지 조치가 시행되거나 논의되고 있는 중
- 인도에서는 틱톡을 포함한 59개 중국 앱이 금지되었으며, 미국에서는 공무원 및 정부 기관에서 사용하는 기기에 틱톡 사용을 금지하는 법안이 통과
- 미국 의회, 해군, NASA, 펜타곤, 텍사스 주 정부 등도 딥시크 앱의 사용을 금지
- 호주, 이탈리아, 네덜란드, 대만, 한국 등 여러 국가에서도 정부 기기에서의 앱 사용을 금지하는 조치
> 국내에서는 환경부, 보건복지부, 여성가족부, 경찰청 등의 정부 부처와 현대차, 기아, 모비스 등의 기업에서 DeepSeek를 접속할 수 없도록 차단
④ DeepSeek 자체 보안 문제
- DeepSeek 자체적으로도 보안 문제가 보고된 사례가 있음
| 구분 | 설명 |
| 서비스 관련 | - 사이버 공격으로 신규 가입이 불가했었던 시점이 존재 - 민감한 질문에(정치, 역사 등) 언어별로 다르게 답변 - 광범위한 개인정보 수집과 수집된 데이터가 중국 서버에 저장 > 광고주 등과 제한 없는 사용자 정보공유 > 사용자의 모든 정보가 학습데이터로 유입 및 활용 > 중국의 국가정보법에 근거 중국 정부에 의해 사용될 수 있음 |
| 민감정보 외부 노출 | - DeepSeek 데이터베이스가 외부에 공개되어 접근이 가능한 상태로 발견 > 데이터 열람만이 아니라 각종 제어 행위도 가능 > 100만 줄이 넘는 로그에 내부 테이터와 채팅 기록, 비밀 키 등 각종 민감 정보가 포함 |
| 민감정보 탈취 | - 이용자 기기 정보와 키보드 입력 패턴 등을 수집해 중국 내 서버에 저장하는 것이 확인 - iOS 앱은 민감한 사용자 및 기기 정보를 암호화 없이 인터넷으로 전송하는 것이 확인 > 중간자 공격, 스니핑 등 해킹 기법에 쉽게 노출 > 애플의 앱 전송 보안(App Transport Security, ATS) 기능을 비활성화한 상태로 운영 > 하드코딩된 암호화 키와 초기화 벡터(initialization vector)의 재사용 |
| 부정 사용 | - 탈옥 방법이 공개 - DeepSeek-R1에 대한 안전성(Safety) 및 보안성(Security) 평가를 실시 > Jailbreaking(탈옥) 공격 성공률 63% > 역할극(Role-Playing) 기반 공격 성공률 83% > 허위 정보(Misinformation) 생성 위험도 89% > JSON 기반의 구조화된 입력(Structure Converting)을 활용한 공격 성공률 82% > 악성 코드 생성(Malware-gen) 요청 프롬프트 78% 성공률 > 사이버 보안(Cyber Security) 관련 취약성 54.6% > 한국어 기반 공격에서 평균적으로 18% 더 높은 취약성 |
⑤ 기타
- 생성형 AI 서비스의 올바르지 못한 사용
> 개인정보, 민감정보 등이 포함된 파일을 업로드하여 사용하는 경우가 있음
> 생성형 AI 도구들의 입력 데이터를 분석한 결과 전체 입력 데이터 중 8.5%가 민감정보를 포함
> 탈옥으로 보안 조치를 우회해 악성코드, 피싱메일, 공격 툴 등을 생성해 악용
4. 시사점
① 경제성 측면
- DeepSeek의 가장 큰 장점은 경제적 효율성으로 기존 AI 모델 대비 저비용, 고효율 AI 훈련 및 운영이 가능
| 구분 | 설명 |
| AI 모델 개발 비용 절감 | - DeepSeek은 GPT-4 수준의 성능을 1/17 수준으로 구현 > AI 스타트업 및 중소기업들도 상대적으로 적은 예산으로 대형 AI 모델을 활용할 수 있는 기회를 제공 |
| 기업의 AI 도입 문턱을 낮춤 | - 고성능 AI 모델을 자체적으로 개발할 여력이 없는 기업에 AI 개발 및 도입에 대한 진입 장벽을 낮춤 > 오픈소스로 제공되기 때문에, 자체적으로 DeepSeek을 커스터마이징하여 활용할 수 있음 |
| AI 산업 경쟁 심화 | - 소수 기업이 AI 모델 개발을 독점하는 구조에서 저비용 오픈소스 모델이 등장함에 따라 다양한 국가와 기업의 경쟁 심화 |
② 보안성 측면
- 경제적 효율성이 뛰어나지만, 보안 리스크가 존재하는 AI 모델로 도입 시 경제성과 보안성 간의 균형을 고려할 필요
| 구분 | 설명 | |
| 개인 및 기업의 대응 전략 |
개인 | - AI 사용 시 민감한 데이터 입력 금지 - 신뢰할 수 있는 AI 도구 사용 검토 |
| 기업 | - 내부 보안 검토 후 AI 도입 결정 - AI 모델 검증 프로세스 도입 - AI 사용 시 데이터 암호화 및 접근 통제 강화 |
|
| 정부 및 공공기관의 대응 전략 |
정부 | - 중국산 AI 모델의 보안성 평가 강화 - 공공기관 내 AI 모델 도입 시 엄격한 검증 절차 수립 - 자국산 AI 모델 개발 투자 확대 |
| 공공기관 | - 외부 AI 도구 사용 시 보안 검토 필수 - 중요 정보가 포함된 데이터는 폐쇄망에서만 사용 |
|
'취약점 > AI, LLM' 카테고리의 다른 글
| ChatGPT Time-Bandit 취약점 (0) | 2025.02.08 |
|---|---|
| Ollama 취약점(CVE-2024-39720, CVE-2024-39722, CVE-2024-39719, CVE-2024-39721, CWE-668, CWE-285) (3) | 2024.11.06 |
| LLM 탈옥 : Crescendo, Deceptive Delight, Context Fusion Attack (CFA) (0) | 2024.10.30 |
| 오픈소스 AI 플랫폼 보안 취약점 (0) | 2024.02.11 |
| 인공지능과 적대적 공격 (Adversarial Attack) (0) | 2023.03.09 |