본 게시글은 책 <악성코드 분석 시작하기> 의 내용을 정리한 글 입니다.
악성코드 분석 시작하기 : 네이버 도서
네이버 도서 상세정보를 제공합니다.
search.shopping.naver.com
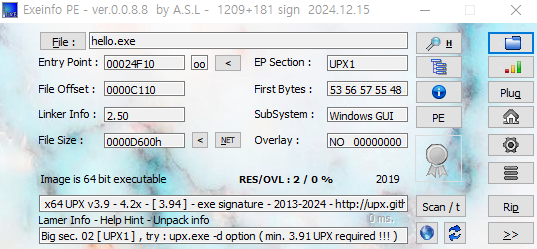
1.6 PE 헤더 정보 조사
- 윈도우 실행 파일은 PE/COFF (Portable Executable/Common Object File Format)를 반드시 준수해야 함
- PE 파일 포맷
> 윈도우 실행 파일(.exe, .dll, .sys, .ocx, drv)이 사용
> 운영 시스템이 메모리로 로딩할 때 필요한 정보를 가진 일련의 구조체와 하위 컴포넌트
- 실행 파일을 컴파일하면 해당 구조체를 설명하는 헤더 (PE 헤더)를 포함
> 실행 파일이 메모리에서 실행될 위치
> 실행 파일의 시작 위치
> 애플리케이션이 의존하는 라이브러리/함수 목록
> 바이너리가 사용하는 리소스와 같은 정보가 포함
- PE 파일 구조체를 이해하기 위한 유용한 자료 링크
> Win32 PE 파일 포맷에 대한 심층적인 조사 - 파트 1 : https://www.delphibasics.info/home/delphibasicsarticles/anin-depthlookintothewin32portableexecutablefileformat-part1
> Win32 PE 파일 포맷에 대한 심층적인 조사 - 파트 2 : https://www.delphibasics.info/home/delphibasicsarticles/anin-depthlookintothewin32portableexecutablefileformat-part2
> PE 헤더와 구조 : https://www.openrce.org/reference_library/files/reference/PE%20Format.pdf
> PE101 - 윈도우 실행 파일 공략 : https://github.com/corkami/pics/blob/master/binary/pe101/pe101ko.pdf
- PE 구조와 그 하위 컴포넌트를 검사하고 수정할 수 있는 몇 가지 도구
> CFF Explorer : https://ntcore.com/explorer-suite/
> PE Internals : https://www.andreybazhan.com/pe-internals.html
> PPEE(puppy) : https://www.mzrst.com/
> PEBrowse Professional : https://download.cnet.com/developer/smidgeonsoft/i-6276008
파일 의존성과 임포트 조사
- 악성코드는 파일, 레지스트리, 네트워크 등과 상호작용하며, 이를 위해 운영 시스템에서 제공하는 함수에 많이 의존
- 윈도우는 API로 불리는 함수를 임포트하며, 상호작용을 위해 동적 링크 라이브러리 (DLL, Dynamic Link Library) 파일이 필요
> DLL에서 여러 함수를 임포트 (Import) 하거나 호출
> 악성코드가 의존하고 있는 DLL과 그런 DLL이 임포트하고 있는 API 함수를 조사하면 악성코드의 기능과 성능, 실행 중 예상할 수 있는 기능을 알 수 있음
- 윈도우 실행 파일의 파일 의존성은 PE 파일 구조의 임포트 테이블에 저장
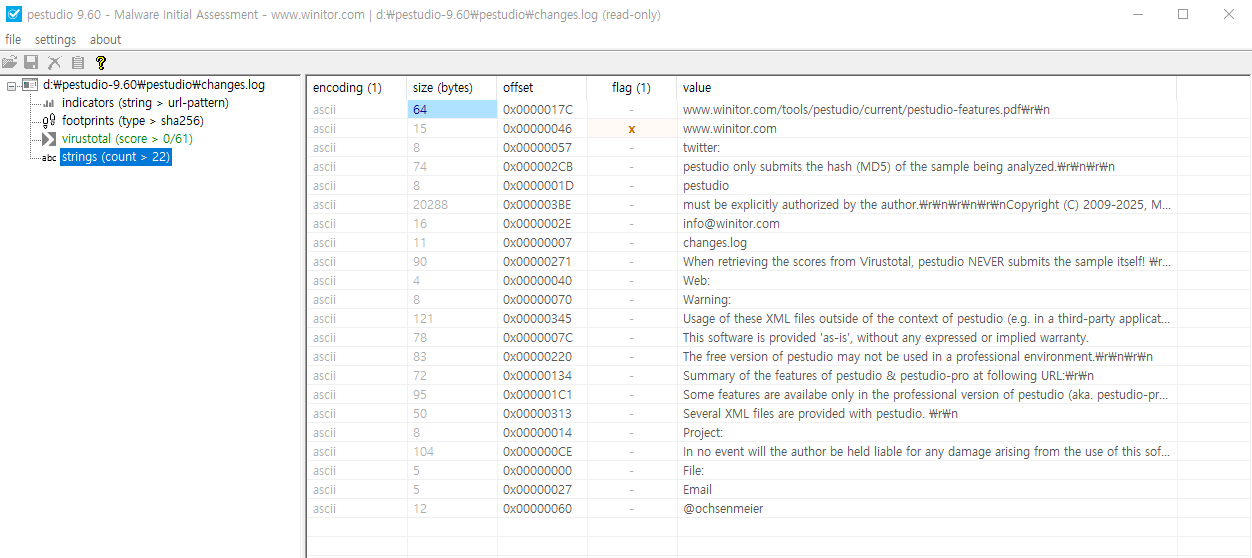
> pestudio의 libraries 버튼을 클릭하면 의존성을 가진 모든 DLL 파일과 각 DLL에서 임포트한 함수의 수를 보여줌

> imports 버튼을 클릭하면 DLL에서 임포트한 API를 표시

- 때때로 악성코드는 LoadLibrary() 또는 LdrLoadDLL()과 같은 API를 호출해서 실행 중 명시적으로 DLL 로드 가능
- 또는, GetProcAddress() API를 사용해 함수 주소를 확인할 수 있음
> 실행 중 로드한 DLL의 정보는 PE 파일의 임포트 테이블에 나타나지 않음
> 윈도우 API 함수와 그 함수의 기능 정보 참고 : https://learn.microsoft.com/ko-kr/search/
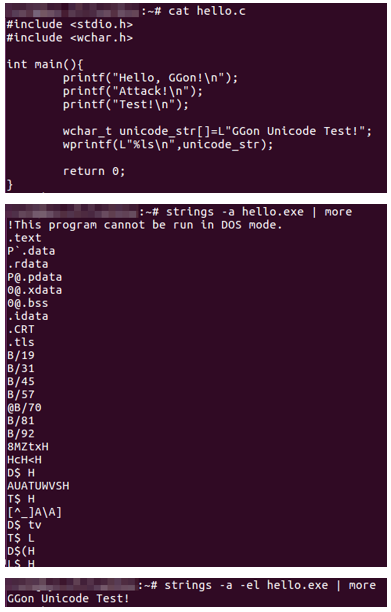
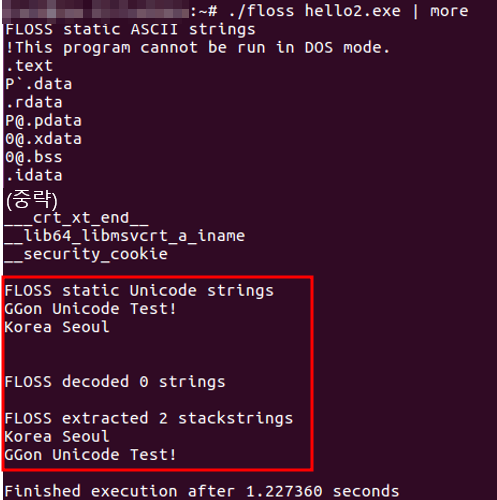
- Python을 이용해 DLL 파일과 임포트한 함수를 나열할 수 있으며, pefile 모듈을 사용
import pefile
import sys
# 명령행 인자 체크
if len(sys.argv) != 2:
print("Usage: python script.py <filename>")
sys.exit(1)
mal_file = sys.argv[1]
def enum_import(mal_file):
try:
# PE 파일 로드
pe = pefile.PE(mal_file)
# Import Table이 존재하는지 확인
if hasattr(pe, 'DIRECTORY_ENTRY_IMPORT'):
print(f"[+] {mal_file} Import Table Found")
for entry in pe.DIRECTORY_ENTRY_IMPORT:
print(f"DLL : {entry.dll.decode('utf-8')} ({len(entry.imports)})")
for i, imp in enumerate(entry.imports):
if imp.name is not None:
print(f" {i + 1}. {imp.name.decode('utf-8')}")
else:
print(f" {i + 1}. Ordinal: {imp.ordinal}")
print()
else:
print("[-] No Import Table Found")
except FileNotFoundError:
print("[-] File not found.")
except pefile.PEFormatError:
print("[-] Invalid PE file.")
except Exception as e:
print(f"[-] Error: {e}")
if __name__ == '__main__':
enum_import(mal_file)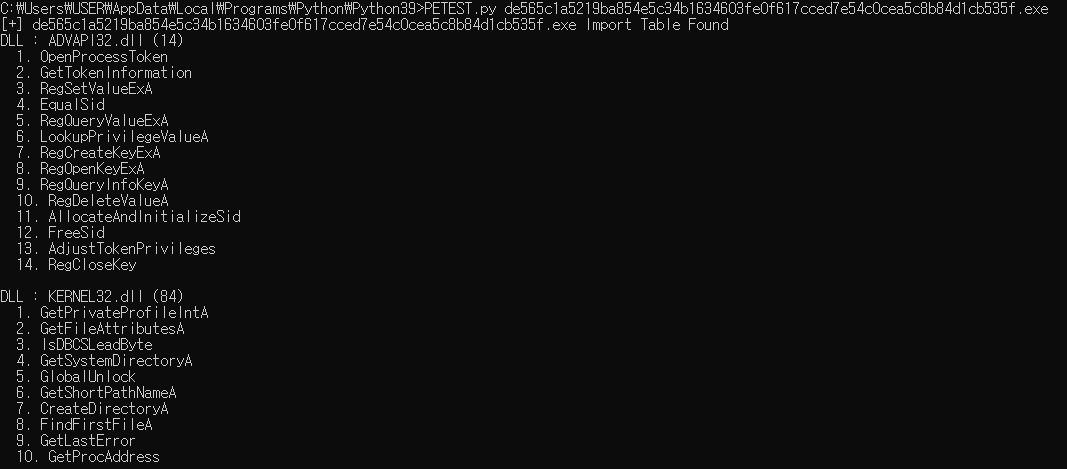
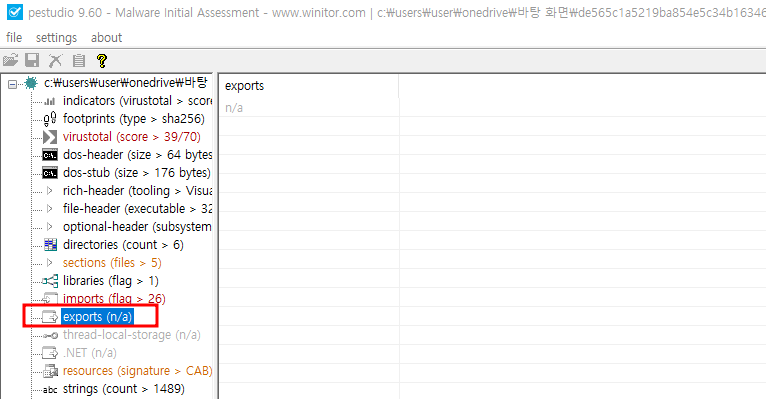
익스포트 (Export) 조사
- 실행 파일과 DLL은 다른 프로그램에서 사용할 수 있는 함수를 익스포트 (Export)할 수 있음
> 일반적으로 DLL은 실행 파일이 임포트할 수 있는 함수 (익스포트)를 노출
> DLL은 단독으로 실행할 수 없기 때문에 호스트 프로세스를 통해 실행
> 공격자는 악의적인 함수를 익스포트하는 DLL을 자주 생성
※ 익스포트 함수명이 매번 악성코드의 기능에 대한 힌트를 주는 것은 아님
- pestudio의 exports 메뉴에서 확인 가능
> Python 예시 참조
import pefile
import sys
# 명령행 인자 체크
if len(sys.argv) != 2:
print("Usage: python script.py <filename>")
sys.exit(1)
mal_file = sys.argv[1]
def enum_import(mal_file):
try:
# PE 파일 로드
pe = pefile.PE(mal_file)
# Import Table이 존재하는지 확인
if hasattr(pe, 'DIRECTORY_ENTRY_IMPORT'):
print(f"[+] {mal_file} Import Table Found")
for entry in pe.DIRECTORY_ENTRY_IMPORT:
print(f"DLL : {entry.dll.decode('utf-8')} ({len(entry.imports)})")
for i, imp in enumerate(entry.imports):
if imp.name is not None:
print(f" {i + 1}. {imp.name.decode('utf-8')}")
else:
print(f" {i + 1}. Ordinal: {imp.ordinal}")
print()
else:
print("[-] No Import Table Found")
# Export Table이 존재하는지 확인
if hasattr(pe, 'DIRECTORY_ENTRY_EXPORT'):
print(f"[+] {mal_file} Export Table Found")
for entry in pe.DIRECTORY_ENTRY_EXPORT.symbols:
if entry.name is not None:
print(f"DLL : {entry.name.decode('utf-8')}")
else:
print(f"Ordinal : {entry.ordinal}")
else:
print("[-] No Export Table Found")
except FileNotFoundError:
print("[-] File not found.")
except pefile.PEFormatError:
print("[-] Invalid PE file.")
except Exception as e:
print(f"[-] Error: {e}")
if __name__ == '__main__':
enum_import(mal_file)
PE 섹션 테이블과 섹션 조사
- PE 파일의 실제 내용은 섹션 (Section)으로 구분
> 섹션은 코드 (Code)와 데이터 (Data)를 나타내고, 읽기/쓰기와 같은 메모리 내부 속성을 가짐
| 구분 | 설명 |
| 코드 | - 프로세스가 실행할 명령어를 포함 |
| 데이터 | - 읽기/쓰기 프로그램 데이터 (전역변수) - 임포트/익스포트 테이블 - 리소스 등 |
- 각 섹션은 해당 섹션의 목적을 나타내는 고유한 이름을 갖고 있음
> 실행 파일을 컴파일하는 동안 컴파일러는 일관된 섹션 이름을 추가
> PE 파일의 공통 섹션
| 섹션명 | 설명 |
| .text 또는 CODE | - 실행 코드를 포함 |
| .data 또는 DATA | - 읽기/쓰기 데이터와 전역 변수 포함 |
| .rdata | - 읽기 전용 데이터를 포함. 때에 따라 임포틑 또는 익스포트 정보 포함 |
| .idata | - 존재한다면 임포트 테이블 포함. 존재하지 않으면, .rdata 섹션에서 탐색 가능 |
| .edata | - 존재한다면 익스포트 정보 포함. 존재하지 않으면, .rdata 섹션에서 탐색 가능 |
| .rsrc | - 실행 파일에서 사용하는 아이콘, 대화창, 메뉴, 문자열 등의 리소스 |
> 섹션명은 사람을 위한 것으로 운영 시스템에서는 사용하지 않으며, 공격자 또는 난독화 소프트웨어가 섹션명을 변경할 수 있음
- 섹션에 대한 정보 (섹션명, 섹션의 위치, 특징)는 PE 헤더에 있는 섹션 테이블 (Section Table)에 존재
> pestudio의 sections 메뉴에서 섹션 테이블에서 추출한 섹션 정보와 그 속성 (읽기/쓰기)을 표시
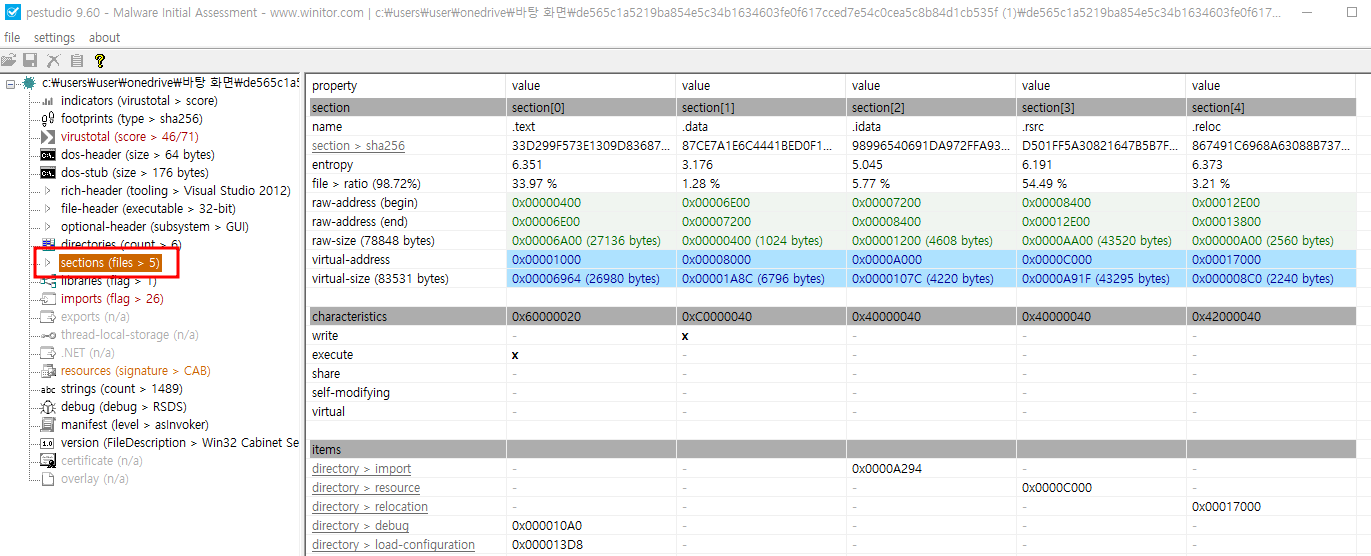
> 섹션 테이블 필드
| 필드 | 설명 |
| name | - 섹션 이름 |
| virtual-size | - 메모리에 로딩할 때 섹션의 크기 |
| virtual-address | - 섹션을 메모리 어디에서 찾을 수 있는지 나타내는 상대적 가상 주소(실행 파일 베이스 주소에서 얼마나 떨어져 있는지를 나타내는 오프셋) |
| raw-size | - 해당 섹션이 디스크에 존재할 때의 크기 |
| raw-data | - 파일에서 해당 섹션을 찾을 수 있는 오프셋 |
| entry-point | - 코드가 실행을 시작하는 RVA(Relatve Virtual Address, 상대적 가상 주소). 일반적으로 .text 섹션에 존재 |
> 만약 컴파일러에서 생성한 일반적인 섹션명 (.text, .data 등)이 아니라면 의심
> 일반적으로 raw-size와 virtual-size의 크기는 거의 같아야 함
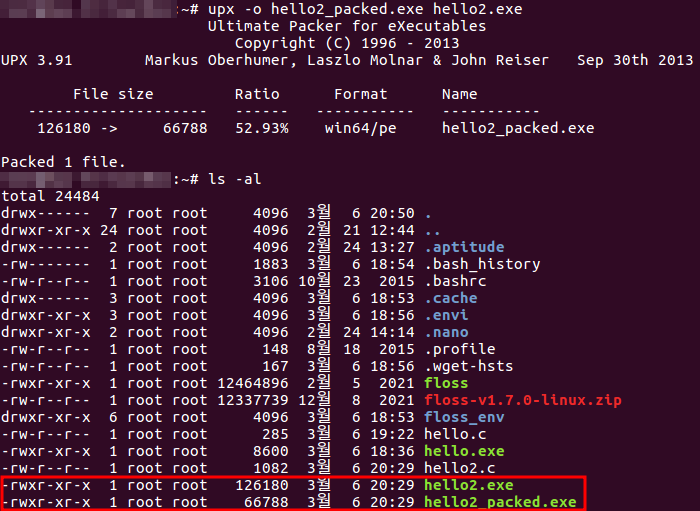
> 만약 raw-size ≒ 0인데, virtual-size가 더 큰 공간을 갖고 있다면, 이는 패킹한 바이너리일 수 있음 (패킹한 바이너리를 실행할 때 패커의 압축 해제 루틴이 런타임 중 압축 해제한 데이터 또는 명령어를 메모리로 복사하기 때문)
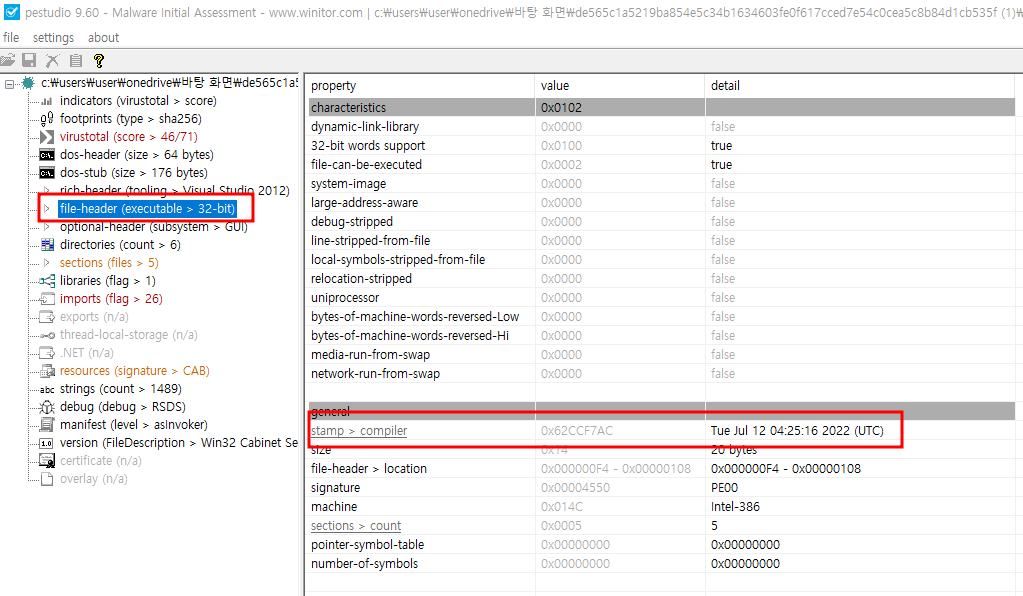
컴파일 타임스탬프 조사
- PE 헤더는 바이너리가 컴파일될 때 생성되는 정보를 포함
- 타임스탬프 (Timestamp) 필드를 조사하면 악성코드가 언제 처음 생성됐는지 알 수 있음
> 공격 활동의 타임라인을 작성할 때 도움을 줌
> 공격자가 실제 타임스탬프를 알 수 없도록 수정해 분석 방해 가능
> pestudio의 file-header 메뉴에 “compiler-stamp” 항목에서 확인 가능
PE 리소스 조사
- 아이콘, 메뉴, 대화장사, 문자열과 같이 실행 파일에 필요한 리소스는 실행 파일의 리소스 섹션 (.rsrc)에 저장
> 공격자는 때때로 추가 바이너리, 미끼 문서, 설정 데이터 같은 정보를 리소스 섹션에 저장
> 리소스 해커 (Resource Hacker)는 의심 바이너리에서 리소스를 조사하고 확인 후 추출할 수 있는 도구

'악성코드 > 분석' 카테고리의 다른 글
| 정적분석 (Static Analysis) #4 (1) | 2025.03.08 |
|---|---|
| 정적분석 (Static Analysis) #2 (0) | 2025.03.06 |
| APAC 지역 기업 대상 FatalRat 피싱 공격 (SalmonSlalom 캠페인) (0) | 2025.02.27 |
| 정적분석 (Static Analysis) (1) | 2025.02.25 |
| 악성코드 분석 개요 (1) | 2025.02.18 |