본 게시글은 책 <악성코드 분석 시작하기> 의 내용을 정리한 글 입니다.
악성코드 분석 시작하기 : 네이버 도서
네이버 도서 상세정보를 제공합니다.
search.shopping.naver.com
1.7 악성코드 비교와 분류
- 의심 바이너리를 이전 분석 샘플 또는 공개, 사설 저장소에 저장된 샘플과 비교하면 악성코드 군, 악성코드의 특징, 이전 분석 샘플과의 유사성을 파악할 수 있음
- 악성 코드 제작자는 빈번하게 악성코드의 미세한 부분을 변경해 해시 값을 완전히 변경하기 때문에 암호 해시(MD5/SAH1/SHA256)를 통한 분류는 유사한 샘플을 식별하는데 도움이 되지 않음
퍼지 해싱을 이용한 악성코드 분류
- 퍼지 해싱 (Fuzz Hashing)은 파일 유사도를 비교하는 방법
> ssdeep을 이용해 샘플에 대한 퍼지 해시를 생성할 수 있으며, 샘플 간의 유사성 비율을 파악하는 데 도움을 줌

> 서로 다른 MD5 해시 값을 가진 실행 파일의 유사도 비교
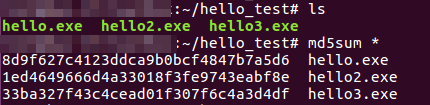
> ssdeep의 상세 일치 모드 (-p 옵션)을 사용해 유사도를 알 수 있음
※ b 옵션 : 명령 출력 결과에 파일 이름만 표시하고, 모든 경로 정보는 생략하는 옵션
※ 샘플 3개 중에서 2개의 샘플이 68%의 유사성을 가짐

- 재귀 모드 (-r)를 사용해 디렉터리와 악성코드 샘플을 포함한 하위 디렉터리에서 ssdeep 실행 가능
※ l 옵션 : 파일 이름에 상대 경로 사용
※ a 옵션 : 점수에 관계없이 모두 표시

> 의심 바이너리를 파일 해시 목록과 비교 가능
# 모든 바이너리의 ssdeep 해시는 all_hashes.txt로 리다이렉션
ssdeep * > all_hashes.txt
# [의심 바이너리]는 all_hashes.txt 파일에 있는 모든 해시와 비교
ssdeep -m all_hashes.txt [의심 바이너리]
> python에서는 python-ssdeep 라이브러리를 사용해 퍼지 해시 계산 가능
import ssdeep
import sys
if len(sys.argv) != 3:
print("Usage: python3 fuzzy_hashing_test.py <file1> <file2>")
sys.exit(1)
# 파일 해시 생성
hash1 = ssdeep.hash_from_file(sys.argv[1])
print("Hash 1:", hash1)
hash2 = ssdeep.hash_from_file(sys.argv[2])
print("Hash 2:", hash2)
# 유사도 비교
similarity = ssdeep.compare(hash1, hash2)
print("Similarity: {}%".format(similarity))임포트 해시를 이용한 악성코드 분류
- 임포트 해싱 (Import Hashing)은 연관성 있는 샘플과 동일한 공격자 그룹에서 사용한 샘플을 식별하는 데 사용
> 임포트 해시 (Import Hash 또는 imphash) : 실행 파일에 있는 라이브러리/임포트 함수 (API) 명과 특유의 순서를 바탕으로 계산한 해시 값
> 동일한 소스와 동일한 방식으로 컴파일할 경우, 동일한 imphash 값을 갖는 경향이 있음
> pestudio의 imphash 확인 가능
※ 임포트 해싱 관련 참고 링크 : https://cloud.google.com/blog/topics/threat-intelligence/tracking-malware-import-hashing/?hl=en

- python에서는 pefile 모듈을 사용해 임포트 해시 계산 가능
import pefile
import sys
pe = pefile.PE(sys.argv[1])
print(pe.get_imphash())- 임포트 API와 퍼지 해싱 기술 (Impfuzzy)을 사용해 악성코드 샘플을 분류하는 방법도 있음
- 동일한 imphash를 가진 파일이 반드시 동일한 위협 그룹으로부터 만들어졌다는 것을 의미하지 않음
섹션 해시를 이용한 악성코드 분류
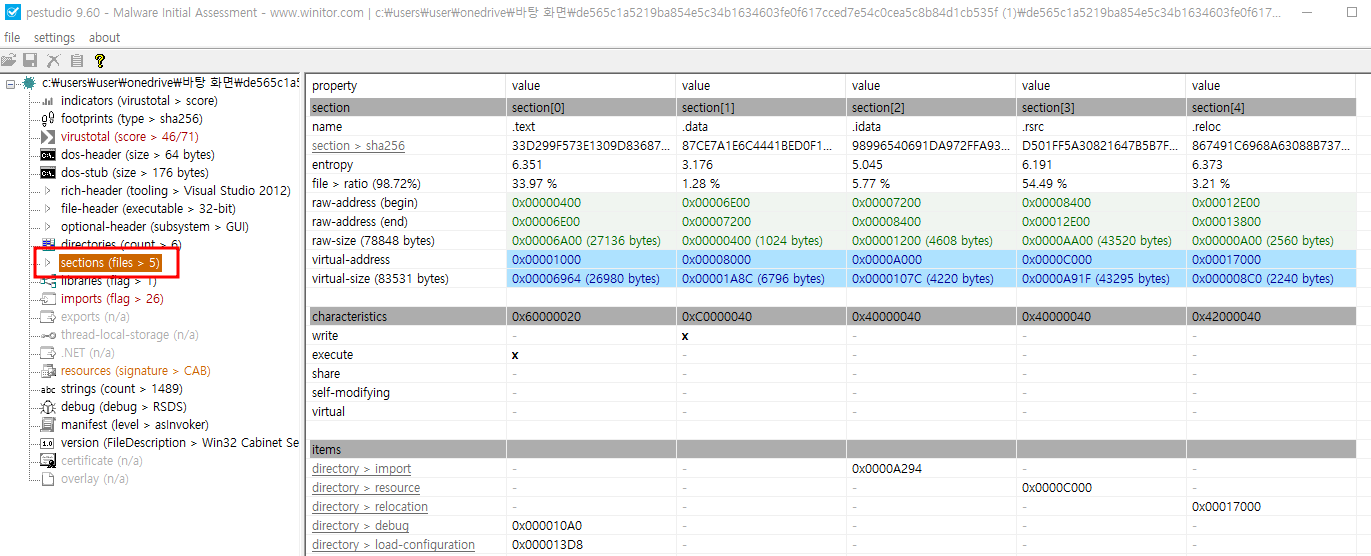
- 임포트 해시와 유사하게 섹션 해시 (Section Hash)도 사용 가능
> pestudio에서 각 센션의 해시 (SHA256) 확인 가능

- python에서는 pefile 모듈을 사용해 섹션 해시 계산 가능
import pefile
import sys
pe = pefile.PE(sys.argv[1])
for section in pe.sections:
print(f"section name : {section.Name.decode('utf-8')}, section hash(md5) : {section.get_hash_md5()}")- 악성코드 샘플을 분석할 때 해당 파일의 임포트 해시(Imphash)와 섹션 해시를 생성하고 저장하는 것이 좋음
> 새로운 샘플을 발견하면 유사점을 판단하고자 해시 비교 가능
YARA를 이용한 악성코드 분류
- 바이너리에 나타나는 고유 문자열과 바이너리 구분자를 기준으로 악성코드를 분류
- YARA는 악성코드를 식별하고 분류하는 강력하는 도구
> 악성코드 샘플에 포함된 텍스트 또는 바이너리 정보를 기반해 YARA 규칙 (Rule) 생성
> 규칙은 로직을 결정하는 문자열과 Boolean 표현식의 집합으로 구성
> 규칙을 작성하면 YARA 유틸리티 또는 yara-python을 사용해 작성한 도구로 파일을 스캐닝할 때 해당 규칙을 이용 가능
※ YARA 규칙 작성에 대한 상세 정보 문서 참고 : https://yara.readthedocs.io/en/v3.3.0/gettingstarted.html
- YARA 규칙 기초 문법
> ~.yara 파일 생성 후 다음 규칙 작성
rule suspicious_strings
{
strings:
$a = "Synflooding"
$b = "Portscanner"
$c = "Keylogger"
condition:
($a or $b or $c)
}
| 구분 | 설명 |
| 규칙 식별자 (Rule Identifier) | - 규칙을 설명하는 이름(=suspicious_strings) - 영문자, 숫자, 밑줄을 포함할 수 있음 > 단, 첫 번째 문자로 숫자를 사용할 수 없음 - 대소문자를 구분하고 128자 초과 불가 |
| 문자열 정의 (String Definition) | - 규칙의 일부인 문자열 (텍스트, 16진수 또는 정규 표현식)이 정의되는 섹션 > 규칙이 문자열에 의존하지 않을 경우 생략 가능 - 각 문자열은 연속된 영문자, 숫자, 밑줄이 뒤따르는 $ 문자로 구성된 식별자(변수)를 가짐(=$a, $b, $c) - 해당 변수들을 조건 섹션에서 사용 |
| 조건 섹션 (Condition Section) | - 규칙의 로직이 위치하는 곳 - 규칙이 일치하거나 일치하지 않는 조건을 지정하는 Boolean 표현식을 포함해야 함 |
- yara 유틸리티를 사용해 YARA 규칙에 따라 파일을 스캔 (ASCII 문자열, 대소문자 구분)
> ASCII와 유니코드 (와이드 문자) 문자열을 탐지하는 규칙의 경우 문자열 옆에 ascii와 wide 수식어 지정
> nocase 수식어는 대소문자를 구분하지 않는 매칭
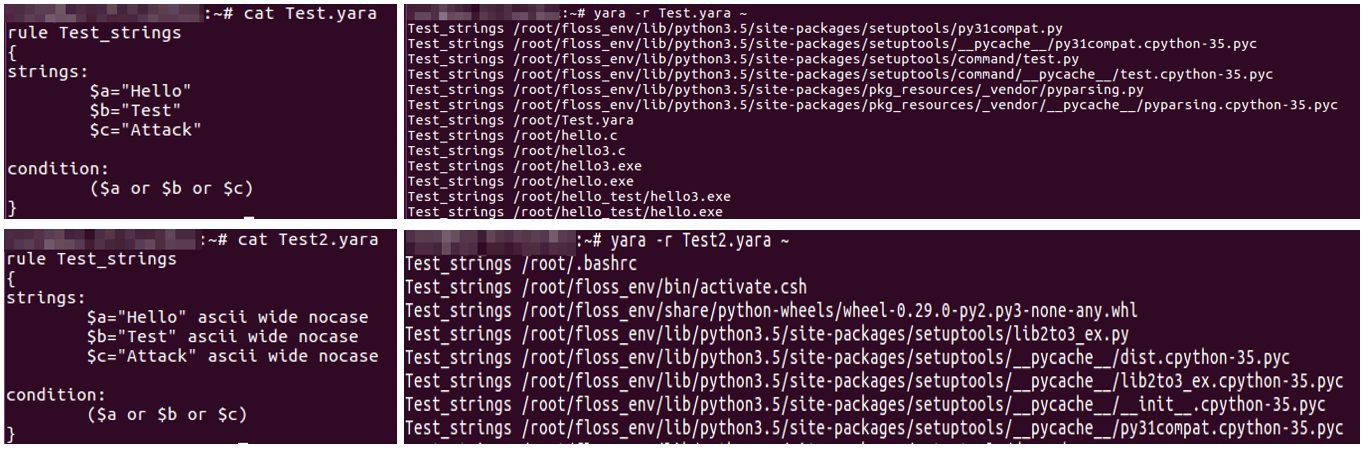
- PE 파일 탐색 YARA Rule
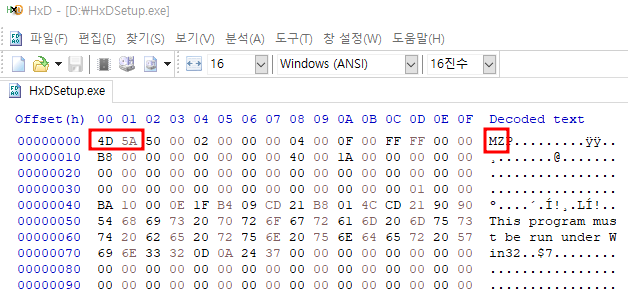
> “$mz at 0”은 YARA가 파일이 시작되는 곳에서 4D 5A 시그니처를 찾음 : PE 파일만 탐색
※ 텍스트 문자열은 "", 16진수 문자열은 중괄호 {}로 묶어야 함
rule PE_Files
{
strings:
$mz = {4D 5A}
condition:
$mz at 0
}
- 정규 표현식을 사용한 URL 형식의 문자열 을 포함한 실행 파일 탐색 YARA rule
rule URL_Detect
{
strings:
$url_pattern = /http:\/\/[a-zA-Z0-9\.-]+\.(com|net|org)/
condition:
$url_pattern
}
- PE 헤더 이후에 특정 바이너리 패턴 일치 YARA rule
> 16진수 문자열이 파일의 1,024바이트 이후에 오프셋 (PE 헤더를 건너뜀)에서 발견할 경우 동작
> filesize는 파일의 끝을 의미
rule Embedded_Office_Document
{
strings:
$mz = {4D 5A}
$a = { D0 CF 11 E0 A1 B1 1A E1 }
condition:
($mz at 0) and $a in (1024..filesize)
}
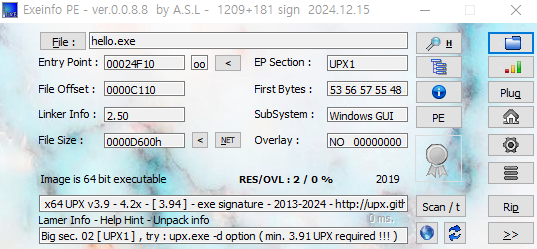
- 패커를 탐지하는 데에도 YARA rule
> 패커 탐지 도구 Exeinfo PE는 userdb.txt라 불리는 일반 텍스트 파일에 저장된 시그니처를 사용
> Exeinfo PE가 UPX 패커를 탐지할 때 사용한 시그니처 포맷의 예
※ ep_only = true : Exeinfo PE가 엔트리 포인트 (코드가 실행을 시작하는 위치)의 프로그램 주소에서만 시그니처를 확인해야 함을 의미
[UPX 2.90 (LZMA)]
signature = 60 BE ?? ?? ?? ?? 8D BE ?? ?? ?? ?? 57 83 CD FF 89 E5 8D 9C 24 ?? ?? ?? ?? 31 C0 50 39 DC 75 FB 46 46 53 68 ?? ?? ?? ?? 57 83 C3 04 53 68 ?? ?? ?? ?? 56 83 C3 04 53 50 C7 03 ?? ?? ?? ?? 90 90
ep_only = true
- 새로운 버전의 YARA는 PE 파일 포맷의 속성과 기능을 사용해 PE 파일을 위한 규칙을 생성할 수 있는 PE 모듈 지원
> 다음 방법을 사용하면 Exeinfo PE의 userdb.txt에 있는 모든 패커 시그니처를 YARA 규칙으로 변환 가능
※ UserDB.txt(PEiD 도구에서 사용)를 YARA 규칙으로 변환하는 Python 코드 참고 : https://github.com/DidierStevens/DidierStevensSuite/blob/master/peid-userdb-to-yara-rules.py
import "pe"
rule UPX_290_LZMA
{
meta :
description = "detect upx packer 2.90"
ref = "userdb.txt file from the Exeinfo PE"
strings:
$a = {60 BE ?? ?? ?? ?? 8D BE ?? ?? ?? ?? 57 83 CD FF 89 E5 8D 9C 24 ?? ?? ?? ?? 31 C0 50 39 DC 75 FB 46 46 53 68 ?? ?? ?? ?? 57 83 C3 04 53 68 ?? ?? ?? ?? 56 83 C3 04 53 50 C7 03 ?? ?? ?? ?? 90 90}
condition:
$a at pe.entry_point
}
- 모든 파일의 패턴을 감지하는 데 사용 가능
rule Gh0stRat
{
meta
description = "Gh0stRat_communications"
strings:
$gst1 = { 8D ?? ?? 5? 8B ?? ?? ?? ?? ?? 81 C? ?? ?? ?? ?? E8 ?? ?? ?? ?? 8B ?? ?? ?? ?? ?? 89 ?? ?? ?? ?? ?? 6A ?? 8D ?? ?? ?? ?? ?? E8 ?? ?? ?? ?? C7 ?? ?? ?? ?? ?? ?? C7 ?? ?? ?? ?? ?? ?? 8B ?? ?? ?? ?? ?? 8B ?? ?? ?? ?? ?? C1 ?? ?? 8B ?? ?? ?? ?? ?? 8D ?? ?? ?? ?? ?? ?? 5? 8D ?? ?? E8 ?? ?? ?? ?? 8B ?? ?? ?? ?? ?? 8B ?? ?? ?? ?? ?? C1 ?? ?? 8B ?? ?? ?? ?? ?? 8B ?? ?? ?? ?? ?? ?? 89 ?? ?? 8B ?? ?? ?? ?? ?? 8B ?? ?? ?? ?? ?? C1 ?? ?? 8B ?? ?? ?? ?? ?? 8D ?? ?? ?? ?? ?? ?? 5? 8D ?? ?? E8 ?? ?? ?? ?? 8B ?? ?? ?? ?? ?? 8B ?? ?? ?? ?? ?? C1 ?? ?? 8B ?? ?? ?? ?? ?? 8B ?? ?? ?? ?? ?? ?? 89 ?? ?? 8D ?? ?? ?? ?? ?? E8 ?? ?? ?? ?? 83 ?? ?? 0F 85 }
$gst2 = { 5? 8B ?? 6A ?? 68 ?? ?? ?? ?? 64 ?? ?? ?? ?? ?? 5? 64 ?? ?? ?? ?? ?? ?? 83 ?? ?? 89 ?? ?? 8B ?? ?? E8 ?? ?? ?? ?? 8D ?? ?? E8 ?? ?? ?? ?? C7 ?? ?? ?? ?? ?? ?? 8D ?? ?? 5? E8 ?? ?? ?? ?? 5? 8B ?? ?? 81 C? ?? ?? ?? ?? E8 ?? ?? ?? ?? 6A ?? 6A ?? 6A ?? 6A ?? 8D ?? ?? E8 ?? ?? ?? ?? 5? 8B ?? 89 ?? ?? 8D ?? ?? 5? E8 ?? ?? ?? ?? 8B ?? ?? 81 C? ?? ?? ?? ?? E8 ?? ?? ?? ?? 6A ?? 6A ?? 68 ?? ?? ?? ?? 68 ?? ?? ?? ?? 8D ?? ?? 5? E8 ?? ?? ?? ?? 89 ?? ?? 8B ?? ?? 89 ?? ?? C6 ?? ?? ?? 8B ?? ?? E8 ?? ?? ?? ?? 5? 8D ?? ?? E8 ?? ?? ?? ?? 89 ?? ?? C6 ?? ?? ?? 8D ?? ?? E8 ?? ?? ?? ?? 83 ?? ?? ?? 0F 84 }
$gst3 = { 5? 8B ?? 6A ?? 68 ?? ?? ?? ?? 64 ?? ?? ?? ?? ?? 5? 64 ?? ?? ?? ?? ?? ?? 83 ?? ?? 89 ?? ?? 6A ?? 8B ?? ?? E8 ?? ?? ?? ?? 8D ?? ?? E8 ?? ?? ?? ?? C7 ?? ?? ?? ?? ?? ?? 6A ?? 68 ?? ?? ?? ?? 68 ?? ?? ?? ?? 68 ?? ?? ?? ?? 8D ?? ?? 5? E8 ?? ?? ?? ?? 89 ?? ?? 8B ?? ?? 89 ?? ?? C6 ?? ?? ?? 8B ?? ?? E8 ?? ?? ?? ?? 5? 8D ?? ?? E8 ?? ?? ?? ?? 89 ?? ?? C6 ?? ?? ?? 8D ?? ?? E8 ?? ?? ?? ?? 83 ?? ?? ?? 0F 84 }
$gst4 = { 66 ?? ?? ?? ?? ?? ?? 66 ?? ?? ?? ?? ?? ?? 0F BF ?? ?? ?? ?? ?? 83 ?? ?? 5? E8 ?? ?? ?? ?? 83 ?? ?? 89 ?? ?? ?? ?? ?? 0F BF ?? ?? ?? ?? ?? 5? 8B ?? ?? ?? ?? ?? 5? 8D ?? ?? ?? ?? ?? E8 ?? ?? ?? ?? 0F BF ?? ?? ?? ?? ?? 8B ?? ?? ?? ?? ?? C6 ?? ?? ?? 8B ?? ?? ?? ?? ?? 5? 8B ?? ?? ?? ?? ?? 81 C? ?? ?? ?? ?? E8 ?? ?? ?? ?? 8B ?? ?? ?? ?? ?? 5? E8 ?? ?? ?? ?? 83 ?? ?? 8D ?? ?? ?? ?? ?? E8 }
$any_variant = /.{5,16}\x00\x00..\x00\x00\x78\x9c
condition:
any of (gst*) or ($any_variant)
}'악성코드 > 분석' 카테고리의 다른 글
| Fast Flux 공격 (0) | 2025.04.12 |
|---|---|
| Ragnar Loader 분석 보고서 (0) | 2025.03.12 |
| 정적분석 (Static Analysis) #3 (1) | 2025.03.07 |
| 정적분석 (Static Analysis) #2 (0) | 2025.03.06 |
| APAC 지역 기업 대상 FatalRat 피싱 공격 (SalmonSlalom 캠페인) (0) | 2025.02.27 |